QII Computation Parameters¶
This notebook will help you gain an understanding of how to tune the parameters involved in computing QIIs.
There are two main parameters used for QII computation:
- number of default influences: The number of data points (aka rows) that we compute QIIs for. When increased, more data points will be used for any QII analysis.
- number of samples: A parameter used internally during QII computation. When increased, it increases the accuracy of the approximations.
Both of these parameters are project-level settings which also slow computations proportionally. That is, if the number of samples is doubled, the runtime should double as well.
Changing the parameters in the TruEra Web App¶
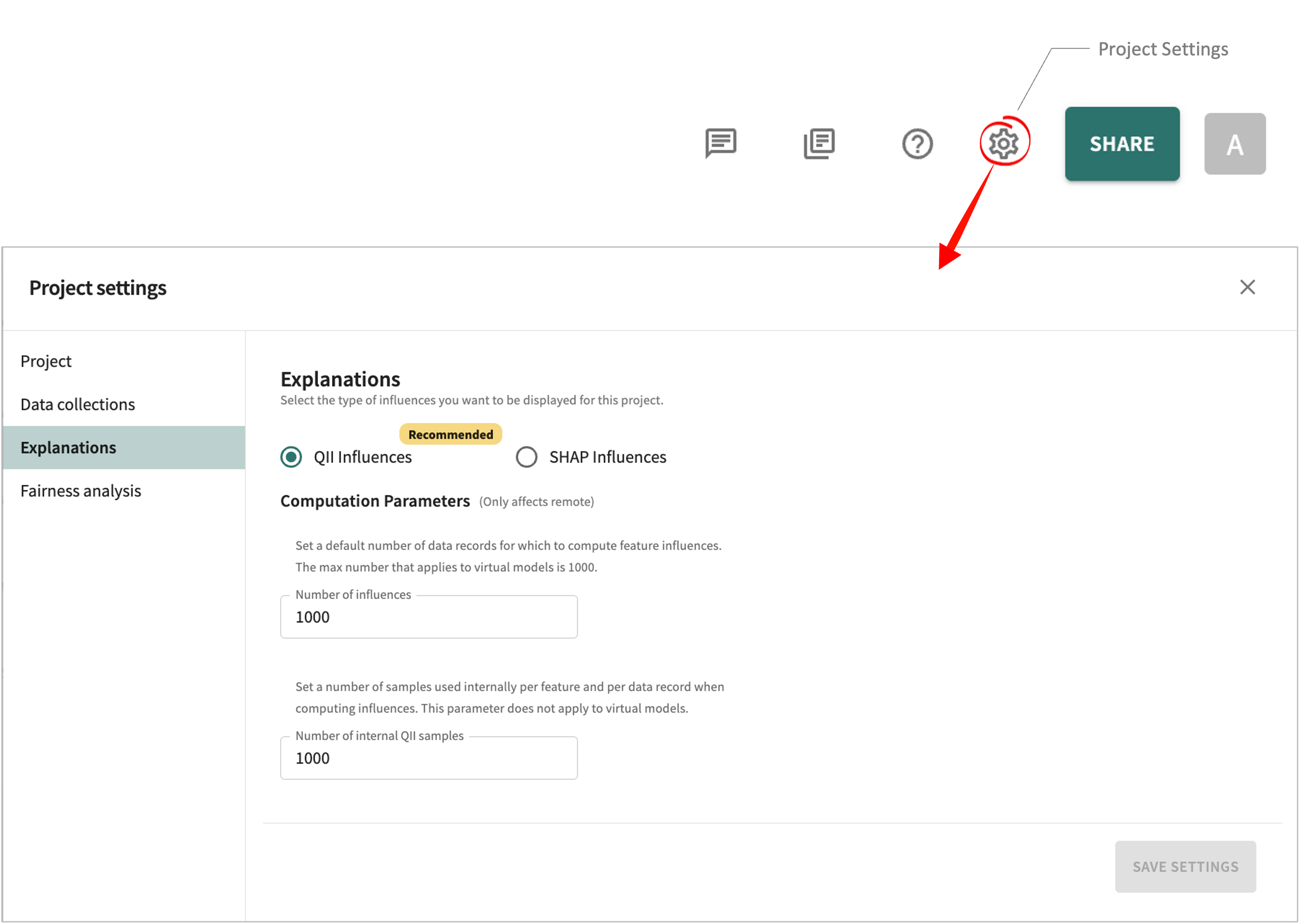
In the Web App toolbar, click Project Settings and scroll down to Analysis:
Changing the parameters in the Python SDK¶
In the Python SDK, the settings can be accessed and changed via:
- number of default influences:
get_num_default_influencesandset_num_default_influences. - number of samples:
get_num_internal_qii_samplesandset_num_internal_qii_samples.
Setting Up QII with the SDK¶
First, if you haven't already done so, install the TruEra Python SDK.
Next, set up QII by creating a simple project and model with the data from the sklearn California Housing dataset.
# FILL ME!
TRUERA_URL = "<TRUERA_URL>"
TOKEN = '<AUTH_TOKEN>'
from truera.client.truera_workspace import TrueraWorkspace
from truera.client.truera_authentication import TokenAuthentication
auth = TokenAuthentication(TOKEN)
tru = TrueraWorkspace(TRUERA_URL, auth)
import pandas as pd
from sklearn.datasets import fetch_california_housing
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_error
from truera.client.ingestion import ColumnSpec
data_bunch = fetch_california_housing()
XS = pd.DataFrame(data=data_bunch["data"], columns=data_bunch["feature_names"])
YS = pd.DataFrame(data=data_bunch["target"], columns=["labels"])
data_all = XS.merge(YS, left_index=True, right_index=True).reset_index(names="id")
tru.add_project("California Housing", score_type="regression")
tru.add_data_collection("sklearn_data")
tru.add_data(
data_all,
data_split_name="all",
column_spec=ColumnSpec(
id_col_name="id",
pre_data_col_names=XS.columns.to_list(),
label_data_col_names=YS.columns.to_list()
)
)
MODEL = GradientBoostingRegressor()
MODEL.fit(XS, YS)
tru.add_python_model("GBM", MODEL)
First let's use only a single sample with 300 explanation instances.
tru.set_num_internal_qii_samples(1)
tru.set_num_default_influences(300)
tru.get_explainer("all").plot_isp("MedInc")
Now compare that to when we use 1000 samples with 1000 explanation instances. The 1000x increase in samples reduces the noise of our estimate and the 300 to 1000 increase in explanation instances increases the number of points.
tru.set_num_internal_qii_samples(1000)
tru.set_num_default_influences(1000)
tru.get_explainer("all").plot_isp("MedInc")