Python SDK Technical Reference¶
This reference provides pertinent technical specifications regarding each TruEra Python SDK method and function. Each API call is listed in the navigator panel on the right under Table of contents in alphabetical order, organized by class.
TrueraWorkspace (BaseTrueraWorkspace)
¶
Workspace for Truera computations.
__init__(self, connection_string, authentication, log_level=20, workspace_name='', thread_pool_max_workers=4, **kwargs)
special
¶
Construct a new TruEra workspace.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
connection_string |
str |
URL of the TruEra deployment. Defaults to None. |
required |
authentication |
TrueraAuthentication |
Credentials to connect to TruEra deployment. Defaults to None. |
required |
log_level |
int |
Log level (defaults to |
20 |
**verify_cert |
bool|str |
When set to |
required |
Exceptions:
| Type | Description |
|---|---|
ValueError |
Raised if exactly one of connection_string and authentication is None. |
activate_client_setting(self, setting_name)
inherited
¶
Activates a setting for client side behavior.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
setting_name |
str |
Client setting to activate. |
required |
add_credential(self, name, secret, identity=None)
¶
[Alpha] Add a new credential to TruEra product. The credential is saved in a secure manner and is used to authenticate with the data source to be able to perform various operations (read, filter, sample etc.).
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
name |
Friendly name of the credential. |
required | |
secret |
The secret to be stored. |
required | |
identity |
Identity portion of the secret. Not needed in all cases. Defaults to None. |
None |
Returns:
| Type | Description |
|---|---|
Credential |
Returns an object with the credential name and id. The secret is not stored in this object. |
add_data(self, data, *, data_split_name, column_spec, model_output_context=None, idempotency_id=None, **kwargs)
¶
Add data by either creating a new split or appending to an existing split. The split will be set in the current context.
ColumnSpec/NLPColumnSpec and ModelOutputContext classes can be imported from truera.client.ingestion.
Alternatively column_spec and model_output_context can be specified as Python dictionaries.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
data |
Union[pd.DataFrame, 'Table'] |
A pd.DataFrame or Table containing the data to be added. |
required |
data_split_name |
str |
The name of the split to be created or appended to. |
required |
column_spec |
Union[ColumnSpec, NLPColumnSpec, Mapping[str, Union[str, Sequence[str]]]] |
The ColumnSpec or NLPColumnSpec mapping column names in the data to corresponding data kind. Parameters include: id_col_name, timestamp_col_name, pre_data_col_names, post_data_col_names, prediction_col_names, label_col_names, extra_data_col_names, feature_influence_col_names, token_influence_col_names, tags_col_name, token_col_name, sentence_embeddings_col_name |
required |
model_output_context |
Optional[Union[ModelOutputContext, dict]] |
Contextual information about data involving a model, such as the model name and score type. This argument can be omitted in most cases, as the workspace infers the appropriate values from the context. |
None |
idempotency_id |
Optional[str] |
Optional string to guarantee idempotent operations. |
None |
add_data_collection(self, data_collection_name, pre_to_post_feature_map=None, provide_transform_with_model=None, schema=None)
¶
Creates and sets the current data collection to use for all operations in the workspace. Must specify feature mapping if some data transformation is being done.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
data_collection_name |
str |
Name of the data collection. |
required |
schema |
Optional[Schema] |
Schema of the data collection. |
None |
Exceptions:
| Type | Description |
|---|---|
ValueError |
Raised if no project is associated with the current workspace. Use set_project to set the correct project. |
Examples:
>>> tru.set_project("Project Name")
>>> schema = Schema(...)
>>> tru.add_data_collection(
data_collection_name="Data Collection Name",
schema=schema
)
add_data_source(self, name, uri, credential=None, **kwargs)
¶
Add a new data source in the system.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
name |
str |
Friendly name of the data source. |
required |
uri |
str |
URI describing the location of the data source. For local files this can be file:///path/to/my/file or /path/to/my/file For files stored in Azure Storage Blobs the expected path is wasb://container@account.blob.core.windows.net/blob |
required |
credential |
Credential |
Provide the credential object if the data source requires authentication to read from it. Defaults to None. |
None |
**format |
str |
The format in which the file (local) or blob (AWS S3, Azure WASB etc.) are stored in. |
required |
**first_row_is_header |
bool |
For text based delimited files (csv, tsv etc.), indicates if the first row provides header information. Defaults to True. |
required |
**column_delimiter |
str |
For text based delimited files (csv, tsv etc.), provides the delimiter to separate column values. Defaults to ','. |
required |
**quote_character |
str |
For text based delimited files (csv, tsv etc.), if quotes are used provide the quote character. Defaults to '"'. |
required |
**null_value |
str |
For text based delimited files (csv, tsv etc.), the string that signifies null value. Defaults to 'null'. |
required |
**empty_value |
str |
For text based delimited files (csv, tsv etc.), the string that signifies empty value. Defaults to '""'. |
required |
**date_format |
str |
For text based delimited files (csv, tsv etc.), if any column has date time, provide the format string. Defaults to 'yyyy-MM-dd-HH |
required |
**account_key |
str |
For reading from Azure Storage Blob (WASB), provide the account_key to be used to read the blob. Not required if |
required |
**database_name |
str |
For reading from sql databases, provide the database name to use. Required for MySQL or Hive data source. |
required |
**table_name |
str |
For reading from sql databases, provide the table name to use. Required for MySQL or Hive data source. |
required |
 ssZZ'.
ssZZ'.Exceptions:
| Type | Description |
|---|---|
ValueError |
Raised if the current project is a local project. |
Returns:
| Type | Description |
|---|---|
Table |
Returns a Table object which allows interaction with the attached data. |
add_extra_data(self, extra_data, extras_col_names, id_col_name, **kwargs)
¶
[Alpha] Add extra data to an existing data split.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
extra_data |
Union[Table, str] |
A Table or URI of file containing the label data.
Table:
Use |
required |
extras_col_names |
Union[str, Sequence[str]] |
Column name(s) for the extra data columns to be ingested. |
required |
id_col_name |
str |
Column name for the unique row identifier in the provided label_data. Used to match labels with corresponding data points. |
required |
**credential |
Credential |
Provide the credential object if the data source requires authentication to read from it. Defaults to None. |
required |
**format |
str |
The format in which the file (local) or blob (AWS S3, Azure WASB etc.) are stored in. |
required |
**first_row_is_header |
bool |
For text based delimited files (csv, tsv etc.), indicates if the first row provides header information. Defaults to True. |
required |
**column_delimiter |
str |
For text based delimited files (csv, tsv etc.), provides the delimiter to separate column values. Defaults to ','. |
required |
**quote_character |
str |
For text based delimited files (csv, tsv etc.), if quotes are used provide the quote character. Defaults to '"'. |
required |
**null_value |
str |
For text based delimited files (csv, tsv etc.), the string that signifies null value. Defaults to 'null'. |
required |
**empty_value |
str |
For text based delimited files (csv, tsv etc.), the string that signifies empty value. Defaults to '""'. |
required |
**date_format |
str |
For text based delimited files (csv, tsv etc.), if any column has date time, provide the format string. Defaults to 'yyyy-MM-dd HH |
required |
**account_key |
str |
For reading from Azure Storage Blob (WASB), provide the account_key to be used to read the blob. Not required if |
required |
**access_key_id |
str |
For reading from a s3 bucket, provide the access key id to be used to read the blob. Not required if |
required |
**secret_access_key |
str |
For reading from a s3 bucket, provide the secret access key to be used to read the blob. Not required if |
required |
**database_name |
str |
For reading from MySQL database, provide the database name to use. Required for MySQL data source. |
required |
**table_name |
str |
For reading from MySQL database, provide the table name to use. Required for MySQL data source. |
required |
**sample_count |
int |
Maximum rows to use when creating the split. Defaults to 5000. |
required |
**sample_kind |
str |
Specifies the strategy to use while sub-sampling the rows. Defaults to "random". |
required |
**timeout_seconds |
int |
Number of seconds to wait for data source. Defaults to 300. |
required |
add_feature_metadata(self, feature_description_map=None, group_to_feature_map=None, missing_values=None, force_update=False)
¶
Upload metadata describing features and feature groupings to the server.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
feature_description_map |
Optional[Mapping[str, str]] |
Map from pre-processed feature name, as provided in the data, to the description of the feature. |
None |
group_to_feature_map |
Optional[Mapping[str, Sequence[str]]] |
Grouping of pre-features for analysis purposes. A key of the map will be a name for the collection of pre-features mapped to. If given, all pre-features must appear in exactly one of the map's value lists. |
None |
missing_values |
Optional[Sequence[str]] |
List of strings to be registered as missing values when reading split data. |
None |
force_update |
bool |
Overwrite any existing feature metadata. |
False |
add_labels(self, label_data, label_col_name, id_col_name, **kwargs)
¶
[Alpha] Add labels to an existing data split.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
label_data |
Union[Table, str] |
A Table or URI of file containing the label data.
Table:
Use |
required |
label_col_name |
str |
Column name for the labels or ground truth in the provided label_data. |
required |
id_col_name |
str |
Column name for the unique row identifier in the provided label_data. Used to match labels with corresponding data points. |
required |
**credential |
Credential |
Provide the credential object if the data source requires authentication to read from it. Defaults to None. |
required |
**format |
str |
The format in which the file (local) or blob (AWS S3, Azure WASB etc.) are stored in. |
required |
**first_row_is_header |
bool |
For text based delimited files (csv, tsv etc.), indicates if the first row provides header information. Defaults to True. |
required |
**column_delimiter |
str |
For text based delimited files (csv, tsv etc.), provides the delimiter to separate column values. Defaults to ','. |
required |
**quote_character |
str |
For text based delimited files (csv, tsv etc.), if quotes are used provide the quote character. Defaults to '"'. |
required |
**null_value |
str |
For text based delimited files (csv, tsv etc.), the string that signifies null value. Defaults to 'null'. |
required |
**empty_value |
str |
For text based delimited files (csv, tsv etc.), the string that signifies empty value. Defaults to '""'. |
required |
**date_format |
str |
For text based delimited files (csv, tsv etc.), if any column has date time, provide the format string. Defaults to 'yyyy-MM-dd HH |
required |
**account_key |
str |
For reading from Azure Storage Blob (WASB), provide the account_key to be used to read the blob. Not required if |
required |
**access_key_id |
str |
For reading from a s3 bucket, provide the access key id to be used to read the blob. Not required if |
required |
**secret_access_key |
str |
For reading from a s3 bucket, provide the secret access key to be used to read the blob. Not required if |
required |
**database_name |
str |
For reading from MySQL database, provide the database name to use. Required for MySQL data source. |
required |
**table_name |
str |
For reading from MySQL database, provide the table name to use. Required for MySQL data source. |
required |
**sample_count |
int |
Maximum rows to use when creating the split. Defaults to 5000. |
required |
**sample_kind |
str |
Specifies the strategy to use while sub-sampling the rows. Defaults to "random". |
required |
**timeout_seconds |
int |
Number of seconds to wait for data source. Defaults to 300. |
required |
add_model(self, model_name, train_split_name=None, train_parameters=None)
¶
Registers and adds a new model in TruEra. By default, the model is "virtual" in that it
does not have an executable model object attached. To add the model object itself, see add_python_model().
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
model_name |
Name of model to create |
required | |
train_split_name |
Optional[str] |
The name of the train split of the model |
None |
train_parameters |
Optional[Mapping[str, Any]] |
Train parameters of the model. Ex. {'n_estimators": 10}"} |
None |
add_model_error_influences(self, error_influence_data, score_type=None, *, data_split_name=None, background_split_name=None, id_col_name=None, timestamp_col_name=None, influence_type=None)
¶
Adds error influence of given score type for the current model and split.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
error_influence_data |
pd.DataFrame |
Feature influence data to add. Must be aligned with the pre-processed data of the given split. |
required |
score_type |
Optional[str] |
Score type of the influences, either |
None |
id_col_name |
Optional[str] |
Column name for the unique identifier of each data point. |
None |
data_split_name |
Optional[str] |
Data split that influences are associated with. If None, defaults to split set in the current context. |
None |
background_split_name |
Optional[str] |
Background data split that influences are computed against. If None, defaults to the base split of the data collection (if this is not explicitly set, it is an ingested split of type "all" or "train"). |
None |
influence_type |
Optional[str] |
Influence algorithm used to generate influences.
If influence type of project is set to "truera-qii", assumes that explanations are generated using truera-qii.
If influence type of project is set to "shap", then |
None |
timestamp_col_name |
Optional[str] |
Column name for the timestamp of each data point. Must be a column of type string or pd.DateTime. Defaults to None. |
None |
add_model_feature_influences(self, feature_influence_data, *, id_col_name, data_split_name=None, background_split_name=None, timestamp_col_name=None, influence_type=None, score_type=None, idempotency_id=None)
¶
Adds feature influence for the current model and split. Assumes influences are calculated for the default score type of the project.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
feature_influence_data |
pd.DataFrame |
Feature influence data to add. Must be aligned with the pre-processed data of the given split. |
required |
id_col_name |
str |
Column name for the unique identifier of each data point. |
required |
data_split_name |
Optional[str] |
Data split that influences are associated with. If None, defaults to split set in the current context. |
None |
background_split_name |
Optional[str] |
Background data split that influences are computed against. If None, defaults to the base split of the data collection (if this is not explicitly set, it is an ingested split of type "all" or "train"). |
None |
timestamp_col_name |
Optional[str] |
Column name for the timestamp of each data point. Must be a column of type string or pd.DateTime. Defaults to None. |
None |
influence_type |
Optional[str] |
Influence algorithm used to generate influences.
If influence type of project is set to "truera-qii", assumes that explanations are generated using truera-qii.
If influence type of project is set to "shap", then |
None |
score_type |
Optional[str] |
The score type to use when computing influences. If None, uses default score type of project. Defaults to None. For a list of valid score types, see |
None |
idempotency_id |
Optional[str] |
Optional string to guarantee idempotent operations. |
None |
add_model_metadata(self, train_split_name=None, train_parameters=None, overwrite=False)
¶
Add or update metadata for the current model in context.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
train_split_name |
Optional[str] |
The name of the train split of the model |
None |
train_parameters |
Optional[Mapping[str, Any]] |
Train parameters of the model. Ex. {'n_estimators": 10}"} |
None |
overwrite |
bool |
Overwrite existing values (if exist). |
False |
add_model_predictions(self, prediction_data, id_col_name=None, *, prediction_col_name=None, data_split_name=None, ranking_group_id_column_name=None, ranking_item_id_column_name=None, score_type=None, idempotency_id=None)
¶
Adds prediction data for the current model. Assumes predictions are calculated for the default score type of the project.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
prediction_data |
Union[pd.DataFrame, Table] |
Prediction data to add. |
required |
id_col_name |
str |
Column name for the unique row identifier in the provided |
None |
prediction_col_name |
Optional[str] |
Column name from which to pull prediction data. Only required if |
None |
data_split_name |
Optional[str] |
Data split that predictions are associated with. If None, defaults to split set in the current context. |
None |
ranking_group_id_column_name |
Optional[str] |
Column name for group id for ranking projects. |
None |
ranking_item_id_column_name |
Optional[str] |
Column name for item id for ranking projects. |
None |
score_type |
Optional[str] |
Specifies the score type for prediction data, if provided. Defaults to None, in which case the score type of the project is used. |
None |
idempotency_id |
Optional[str] |
Optional string to guarantee idempotent operations. |
None |
add_nn_data_split(self, data_split_name, truera_wrappers, split_type='all', *, pre_data=None, label_data=None, label_col_name=None, id_col_name=None, extra_data_df=None)
¶
[Alpha] Upload NN data split to TruEra server.
Examples:
# During NN Ingestion to add a split you will create wrappers
>>> from truera.client.nn.wrappers.autowrap import autowrap
>>> truera_wrappers = autowrap(...) # Use the appropriate NN Diagnostics Ingestion to create this
# Add the data split to the truera workspace
>>> tru.add_nn_data_split(
>>> data_split_name="<split_name>",
>>> truera_wrappers,
>>> split_type="<split_type_train_or_test>"
>>> )
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
data_split_name |
str |
Name of the split to be uploaded. |
required |
truera_wrappers |
base.WrapperCollection |
A Base.WrapperCollection housing a base.Wrappers.SplitLoadWrapper that helps load data files from files. This must be implemented via subclassing the truera.client.nn.wrappers.Base.SplitLoadWrapper |
required |
split_type |
Optional[str] |
The type of the data split. Options are ["all", "train", "test", "validate", "oot", "prod", "custom"]. Defaults to "all". |
'all' |
pre_data |
Optional[Union[np.ndarray, pd.DataFrame]] |
Data. |
None |
label_data |
Optional[pd.DataFrame] |
Label data. |
None |
label_col_name |
Optional[str] |
The column name in |
None |
id_col_name |
Optional[str] |
The column name in |
None |
extra_data_df |
Optional[pd.DataFrame] |
Extra columns which are not used / consumed by the model, but could be used for other analysis like defining segments. |
None |
add_nn_model(self, model_name, truera_wrappers, attribution_config, model=None, train_split_name=None, train_parameters=None, **kwargs)
¶
[Alpha] Upload a NN model to TruEra server. The model is also attached to the workspace as the current model.
Examples:
# During NN Ingestion you will create two objects
>>> from truera.client.nn.client_configs import NLPAttributionConfiguration
>>> attr_config = NLPAttributionConfiguration(...)
>>> from truera.client.nn.wrappers.autowrap import autowrap
>>> truera_wrappers = autowrap(...) # Use the appropriate NN Diagnostics Ingestion to create this
# Add the model to the truera workspace
>>> tru.add_nn_model(
>>> model_name="<model_name>",
>>> truera_wrappers,
>>> attr_config
>>> )
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
model_name |
str |
Name assigned to the model. |
required |
truera_wrappers |
base.WrapperCollection |
A set of wrappers to help truera run your model. The tutorial should help you get them. |
required |
attribution_config |
dict |
An attribution config containing attribution run parameters. |
required |
model |
Optional[Any] |
Your model object. |
None |
train_split_name |
Optional[str] |
The name of the train split of the model. |
None |
train_parameters |
Optional[Mapping[str, Any]] |
Train parameters of the model. Ex. {'n_estimators": 10}"} |
None |
Exceptions:
| Type | Description |
|---|---|
ValueError |
Raised if no project is associated with the current workspace. Use set_project to set the correct project. |
ValueError |
Raised if workspace is not attached to a data_collection. Either attach workspace to a data-collection or provide the data_collection_name. |
ValueError |
Raised if the provided data_collection_name does not exist in the current project. |
add_packaged_python_model(self, model_name, model_dir, *, data_collection_name=None, train_split_name=None, train_parameters=None, verify_model=True, compute_predictions=None, compute_feature_influences=False, compute_for_all_splits=False)
¶
Registers and adds a new model, along with a pre-serialized and packaged executable Python model object. The model is also attached to the workspace as the current model.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
model_name |
str |
Name assigned to the model. |
required |
model_dir |
str |
Directory where packaged model is located. |
required |
data_collection_name |
Optional[str] |
Data collection to attach to the model, by default the data collection attached to the workspace will be used. Defaults to None. |
None |
train_split_name |
Optional[str] |
The name of the train split of the model |
None |
train_parameters |
Optional[Mapping[str, Any]] |
Train parameters of the model. Ex. {'n_estimators": 10}"} |
None |
verify_model |
bool |
Locally verify the model is packaged properly and can operate on existing split data. Defaults to True. |
True |
compute_predictions |
Optional[bool] |
Trigger computations of model predictions on the base/default split of the model's data collection, if such a split exists. Ignored for local models. Defaults to True when using |
None |
compute_feature_influences |
bool |
Trigger computations of model feature influences on the base/default split of the model's data collection, if such a split exists. Ignored for local models. |
False |
compute_for_all_splits |
bool |
If |
False |
add_production_data(self, data, *, column_spec, model_output_context=None, idempotency_id=None, **kwargs)
¶
Add production data.
ColumnSpec and ModelOutputContext classes can be imported from truera.client.ingestion.
Alternatively column_spec and model_output_context can be specified as Python dictionaries.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
data |
Union[pd.DataFrame, 'Table'] |
A pd.DataFrame or Table containing the data to be added. |
required |
column_spec |
Union[ColumnSpec, NLPColumnSpec, Mapping[str, Union[str, Sequence[str]]]] |
The ColumnSpec mapping column names in the data to corresponding data kind. Parameters include: id_col_name, timestamp_col_name, pre_data_col_names, post_data_col_names, prediction_col_names, label_col_names, extra_data_col_names, feature_influence_col_names, token_influence_col_names, tags_col_name, token_col_name, sentence_embeddings_col_name |
required |
model_output_context |
Optional[Union[ModelOutputContext, dict]] |
Contextual information about data involving a model, such as the model name and score type. This argument can be omitted in most cases, as the workspace infers the appropriate values from the context. |
None |
idempotency_id |
Optional[str] |
Optional string to guarantee idempotent operations. |
None |
add_project(self, project, score_type, input_type='tabular', num_default_influences=None)
¶
Adds and sets project to use for the current workspace environment. This will unset the rest of the context (data collection, data split, model, etc) if set prior.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
project |
str |
Name of the project. |
required |
score_type |
str |
Scorer type configuration for the project. Options are ["logits", "probits", "classification", "regression"]. |
required |
input_type |
Optional[str] |
Input data type for the project. Must be one of ["tabular", "time_series_tabular"]. Defaults to "tabular". |
'tabular' |
num_default_influences |
Optional[int] |
Number of influences used by default for most influence-requiring graphs, computations, etc. Note that this will take the first of the provided many from the data split --- therefore, shuffling data splits is generally advised prior to ingestion. If creating a project and left as None, then will be set as 1000. |
None |
Examples:
# Create a probits project
>>> tru.add_project("Project Name", score_type = "probits")
add_python_model(self, model_name, model, transformer=None, *, additional_pip_dependencies=None, additional_modules=None, classification_threshold=None, train_split_name=None, train_parameters=None, verify_model=True, compute_predictions=None, compute_feature_influences=False, compute_for_all_splits=False, **kwargs)
¶
Registers and adds a new model, including the executable model object provided. This method deduces the model framework to appropriately serialize
and upload the model object to TruEra server. Models of supported frameworks can be passed directly.
Supported Model Frameworks: sklearn, xgboost, catboost, lightgbm, pyspark (tree models only).
If you cannot ingest your model via this function due to custom logic, feature transforms, etc., see create_packaged_python_model().
[ALPHA] For frameworks that are not yet supported, or for custom model implementations the prediction
function for the model can be provided as the model.
For binary classifiers, the prediction function should accept a pandas DataFrame as input and produce
a pandas DataFrame as output with the class probabilities and [0, 1] as the column header.
For regression models, the prediction function should accept a pandas DataFrame as input and produce
the result as a pandas DataFrame with "Result" as the column header.
All required dependencies to execute the prediction function should be provide as additional_pip_dependencies.
For example:
add_segment_group(self, name, segment_definitions)
¶
[Alpha] Create a segment group where each segments is defined by an SQL expression.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
name |
str |
The name of the segment group. |
required |
segment_definitions |
Mapping[str, str] |
A dictionary containing the name of the segment and an SQL expression that defines the segment. Supported expressions:
|
required |
Examples:
>>> tru.set_project("Project Name")
>>> tru.set_data_collection("Data Collection Name")
# Add a segment group for Sex
>>> tru.add_segment_group(name = "Sex", segment_definitions = {"Male": "Sex == 'Male'", "Female": "Sex == 'Female'"})
# Add a segment group for Language at Home
>>> tru.add_segment_group("Language at Home", {"English": "LANX == 1", "Not English": "LANX == 2"})
attach_packaged_python_model_object(self, model_object_dir, verify_model=True)
¶
Attaches a pre-serialized and packaged executable model object to the current model, which must be virtual. This effectively "converts" the virtual model to a non-virtual one, as the system can now call the model to generate predictions.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
model_object_dir |
str |
Directory where packaged model object is located. |
required |
verify_model |
bool |
Locally verify the model is packaged properly and can operate on existing split data. Defaults to True. |
True |
attach_python_model_object(self, model_object, additional_pip_dependencies=None, verify_model=True)
¶
Attaches the provided executable model object to the current model, which must be virtual.
This effectively "converts" the virtual model to a non-virtual one, as the system can now call the model to generate predictions.
Supported Model Frameworks: sklearn, xgboost, catboost, lightgbm, pyspark (tree models only).
If you cannot ingest your model object via this function due to custom logic, feature transforms, etc., see attach_packaged_python_model_object().
[ALPHA] For frameworks that are not yet supported, or for custom model implementations the prediction
function for the model can be provided as the model.
For binary classifiers, the prediction function should accept a pandas DataFrame as input and produce
a pandas DataFrame as output with the class probabilities and [0, 1] as the column header.
For regression models, the prediction function should accept a pandas DataFrame as input and produce
the result as a pandas DataFrame with "Result" as the column header.
All required dependencies to execute the prediction function should be provide as additional_pip_dependencies.
For example:
```python
def predict(df):
return pd.DataFrame(my_model.predict_proba(df, validate_features=False), columns=[0, 1])
tru.add_python_model("my_model", predict, additional_pip_dependencies=["xgboost==1.3.1", "pandas==1.1.1"])
```
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
model_object |
Any |
The Python model object or the prediction function to attach. Supported frameworks are catboost, lightgbm, sklearn and xgboost, and tree-based PySpark models. For prediction function, please see the description above. |
required |
additional_pip_dependencies |
Optional[Sequence[str]] |
List of pip dependencies required to execute the model object. If the model object is from a supported framework, the pip dependency for that framework is automatically inferred. If a prediction function is provided as the model, additional pip dependencies are not automatically inferred and must be explicitly provided. Defaults to None. Example: ["pandas==1.1.1", "numpy==1.20.1"] |
None |
verify_model |
bool |
[Alpha] Locally verify the model is packaged properly and can operate on existing split data. Defaults to True. |
True |
cancel_scheduled_ingestion(self, workflow_id)
¶
[Alpha] Cancel a scheduled ingestion.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
workflow_id |
str |
The id of the scheduled ingestion workflow. |
required |
Returns:
| Type | Description |
|---|---|
str |
Returns an object containing the canceled_on timestamp of a workflow. |
compute_all(self, computations=['predictions', 'feature influences', 'error influences'], models=None, data_splits=None, data_collection=None, num_influences=None)
¶
Executes and ingests all specified computations over models and data-splits in a data collection
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
computations |
Sequence[str] |
Types of computations. Defaults to ["predictions", "feature influences", "error influences"]. |
['predictions', 'feature influences', 'error influences'] |
models |
Optional[Sequence[str]] |
Models to compute with. All models in data collection if None. Defaults to None. |
None |
data_splits |
Optional[Sequence[str]] |
Data-splits to compute with. All data-splits in data collection if None. Defaults to None. |
None |
data_collection |
Optional[str] |
Data collection to compute over. Uses data collection in context if None. Defaults to None. |
None |
num_influences |
Optional[int] |
Number of influences to calculate for influence computations. Uses project settings if None. Defaults to None. |
None |
compute_error_influences(self, start=0, stop=None, score_type=None, system_data=False, by_group=False, num_per_group=None, ingest=True)
¶
Compute the error QIIs/shapley-values associated with the current data-split.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
start |
Optional[int] |
The lower bound (inclusive) of the index of points to include. Defaults to 0. |
0 |
stop |
Optional[int] |
The upper bound (exclusive) of the index of points to include. Defaults to None which is interpreted as the total number of points for local projects and the setting for "Number of default influences" for remote projects. |
None |
score_type |
Optional[str] |
The score type to use when computing error influences. If None, infers error score type based on project configuration. Defaults to None. |
None |
system_data |
bool |
Include system data (e.g. timestamps) if available in response. Defaults to False. |
False |
by_group |
bool |
For ranking projects, whether to retrieve data by group or not. Ignored for non-ranking projects. Defaults to False. |
False |
num_per_group |
Optional[int] |
For ranking projects and when |
None |
wait |
Whether to wait for the job to finish. Defaults to True. |
required | |
ingest |
bool |
Whether to ingest computed feature influences. Defaults to True. |
True |
Returns:
| Type | Description |
|---|---|
pd.DataFrame |
The QIIs/shapley-values associated with the current data-split. |
compute_feature_influences(self, start=0, stop=None, score_type=None, system_data=False, by_group=False, num_per_group=None, ingest=True)
¶
Compute the QIIs/shapley-values associated with the current data-split.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
start |
Optional[int] |
The lower bound (inclusive) of the index of points to include. Defaults to 0. |
0 |
stop |
Optional[int] |
The upper bound (exclusive) of the index of points to include. Defaults to None which is interpreted as the total number of points for local projects and the setting for "Number of default influences" for remote projects. |
None |
score_type |
Optional[str] |
The score type to use when computing influences. If None, uses default score type of project. Defaults to None. For a list of valid score types, see |
None |
system_data |
bool |
Include system data (e.g. timestamps) if available in response. Defaults to False. |
False |
by_group |
bool |
For ranking projects, whether to retrieve data by group or not. Ignored for non-ranking projects. Defaults to False. |
False |
num_per_group |
Optional[int] |
For ranking projects and when |
None |
ingest |
bool |
Whether to ingest computed feature influences. Defaults to True. |
True |
Returns:
| Type | Description |
|---|---|
pd.DataFrame |
The QIIs/shapley-values associated with the current data-split. |
compute_feature_influences_for_data(self, pre_data, post_data=None, ys=None, score_type=None, comparison_post_data=None, num_internal_qii_samples=1000, algorithm='truera-qii')
¶
Compute the QIIs/shapley-values for the provided data.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
pre_data |
pd.DataFrame |
A pandas DataFrame containing the human-readable data for which to compute influences. If |
required |
post_data |
Optional[pd.DataFrame] |
A pandas DataFrame containing the model-readable post-processed data that is aligned with the pre-processed data. Can be ignored if model-readable pre-processed data is provided. If providing different pre- and post-processed data, be sure the mapping between them adheres to the feature map of the data collection specified during the data collection's creation. |
None |
ys |
Optional[Union[np.ndarray, pd.Series]] |
Labels for which to compute influences if required by the provided |
None |
score_type |
Optional[str] |
The score type to use when computing influences. If None, defaults to score type of project. Defaults to None. For a list of valid score types, see |
None |
comparison_post_data |
Optional[pd.DataFrame] |
The comparison data to use when computing influences. If None, defaults to a data split of the data collection of type "all" or "train" and failing that uses the base split currently set in this explainer. Defaults to None. |
None |
num_internal_qii_samples |
int |
Number of samples used internally in influence computations. |
1000 |
algorithm |
str |
Algorithm to use during computation. Must be one of ["truera-qii", "tree-shap-tree-path-dependent", "tree-shap-interventional", "kernel-shap"]. Defaults to "truera-qii". |
'truera-qii' |
Returns:
| Type | Description |
|---|---|
pd.DataFrame |
The QIIs/shapley-values. |
compute_predictions(self, start=0, stop=None, system_data=False, ingest=True)
¶
Compute predictions over the current data-split.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
start |
Optional[int] |
The lower bound (inclusive) of the index of points to include. Defaults to 0. |
0 |
stop |
Optional[int] |
The upper bound (exclusive) of the index of points to include. Defaults to None which is interpreted as the total number of rows. |
None |
system_data |
bool |
Include system data (e.g. timestamps) if available in response. Defaults to False. |
False |
by_group |
For ranking projects, whether to retrieve data by group or not. Ignored for non-ranking projects. Defaults to False. |
required | |
num_per_group |
For ranking projects and when |
required | |
ingest |
bool |
Whether to ingest predictions. Defaults to True. |
True |
Returns:
| Type | Description |
|---|---|
The predictions for the current data-split. |
create_packaged_python_model(self, output_dir, model_obj=None, additional_pip_dependencies=None, additional_modules=None, model_path=None, model_code_files=None, **kwargs)
¶
Creates a template of a packaged Python model object to be edited and then uploaded to TruEra server.
Can be used to package either Python model objects, or serialized model data. This workflow should only be used for custom models or to debug model ingestion.
To upload a models of a known framework, it is recommended to use the add_python_model() function.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
output_dir |
str |
Path to the directory to create template. Cannot be an existing directory. |
required |
model_obj |
Optional[Any] |
The Python model object to package. Supported frameworks are catboost, lightgbm, sklearn, xgboost, and tree-based PySpark models. |
None |
additional_pip_dependencies |
Optional[Sequence[str]] |
List of pip dependencies required to execute the model. When model object is from a supported framework, pip dependency for that framework is automatically inferred. If a prediction function is provided as the model, additional pip dependencies are not automatically inferred and must be explicitly provided. Defaults to None. Example: ["pandas==1.1.1", "numpy==1.20.1"]. |
None |
additional_modules |
Optional[Sequence[Any]] |
List of modules not available as pip packages required for the model. These must already be imported. Defaults to None. |
None |
model_path |
Optional[str] |
Path to a model file or directory. Can be a serialized model or a directory containing multiple files of serialized data.
Ignored if |
None |
model_code_files |
Optional[Sequence[str]] |
List of paths to additional files to be packaged with the model. Ignored if |
None |
deactivate_client_setting(self, setting_name)
inherited
¶
Deactivates a setting for client side behavior.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
setting_name |
str |
Client setting to deactivate. |
required |
delete_credential(self, name)
¶
[Alpha] Removes a credential from the TruEra product.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
name |
Friendly name of the credential. |
required |
delete_data_source(self, name)
¶
Delete a data source that was already created in the system.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
name |
str |
The friendly name of the data source. |
required |
delete_model_metadata(self)
¶
Unset train_split_name and train_parameters for the current model in context.
delete_segment_group(self, name)
¶
[Alpha] Delete a segment group.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
name |
str |
The name of the segment group. |
required |
get_client_setting_value(self, setting_name)
inherited
¶
Gets current value of a setting for client side behavior.
get_credential_metadata(self, name)
¶
[Alpha] Get metadata about a credential in the TruEra product. The credential details are not returned.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
name |
Friendly name of the credential. |
required |
Returns:
| Type | Description |
|---|---|
Credential |
Returns an object with the credential name and id. |
get_data_collections(self)
¶
Get all data-collections in the connected project.
Exceptions:
| Type | Description |
|---|---|
ValueError |
Raised if the workspace isn't connected to any project. |
Returns:
| Type | Description |
|---|---|
Sequence[str] |
Name of data-collections in the project. |
get_data_source(self, name)
¶
Get a data source that was already created in the system.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
name |
str |
The friendly name of the data source. |
required |
Exceptions:
| Type | Description |
|---|---|
ValueError |
Raised if the current project is a local project. |
Returns:
| Type | Description |
|---|---|
Table |
Returns a Table object which allows interaction with the attached data. |
get_data_sources(self)
¶
Get list of data sources attached in the current project.
Exceptions:
| Type | Description |
|---|---|
ValueError |
Raised if the current project is a local project. |
get_data_splits(self)
¶
Get all data-splits in the connected data-collection.
Exceptions:
| Type | Description |
|---|---|
ValueError |
Raised if the workspace isn't connected to any project. |
ValueError |
Raised if the workspace isn't connected to any data-collection. |
Returns:
| Type | Description |
|---|---|
Sequence[str] |
Name of data-splits in the project. |
get_default_performance_metrics(self)
¶
Get the default performance metrics of the currently set project.
Returns:
| Type | Description |
|---|---|
Sequence[str] |
Default performance metrics. |
get_error_influences(self, start=0, stop=None, score_type=None, system_data=False, by_group=False, num_per_group=None)
¶
Get the error QIIs/shapley-values associated with the current data-split. Note that, if you set the start and stop, the number of records returned will not be the exact number requested but in the neighborhood of the start and stop limit provided.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
start |
Optional[int] |
The lower bound (inclusive) of the index of points to include. Defaults to 0. |
0 |
stop |
Optional[int] |
The upper bound (exclusive) of the index of points to include. Defaults to None which is interpreted as the total number of points for local projects and the setting for "Number of default influences" for remote projects. |
None |
score_type |
Optional[str] |
The score type of error influences to retrieve. If None, infers error score type based on project configuration. Defaults to None. |
None |
system_data |
bool |
Include system data (e.g. timestamps) if available in response. Defaults to False. |
False |
by_group |
bool |
For ranking projects, whether to retrieve data by group or not. Ignored for non-ranking projects. Defaults to False. |
False |
num_per_group |
Optional[int] |
For ranking projects and when |
None |
Returns:
| Type | Description |
|---|---|
pd.DataFrame |
The QIIs/shapley-values associated with the current data-split. |
get_explainer(self, base_data_split=None, comparison_data_splits=None)
¶
Get the explainer associated with the TruEra workspace.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
base_data_split |
Optional[str] |
The name of the data split to set as the base split for explainer operations. |
None |
comparison_data_splits |
Optional[Sequence[str]] |
The name(s) of the data splits to set as the comparison splits for explainer operations. |
None |
Returns:
| Type | Description |
|---|---|
Explainer |
Explainer for current context of the TruEra workspace. |
get_feature_influences(self, start=0, stop=None, score_type=None, system_data=False, by_group=False, num_per_group=None)
¶
Get the QIIs/shapley-values associated with the current data-split. Note that, if you set the start and stop, the number of records returned will not be the exact number requested but in the neighborhood of the start and stop limit provided.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
start |
Optional[int] |
The lower bound (inclusive) of the index of points to include. Defaults to 0. |
0 |
stop |
Optional[int] |
The upper bound (exclusive) of the index of points to include. Defaults to None which is interpreted as the project setting for "Number of default influences". |
None |
score_type |
Optional[str] |
The score type to use when computing influences. If None, uses default score type of project. Defaults to None. For a list of valid score types, see |
None |
system_data |
bool |
Include system data (e.g. timestamps) if available in response. Defaults to False. |
False |
by_group |
bool |
For ranking projects, whether to retrieve data by group or not. Ignored for non-ranking projects. Defaults to False. |
False |
num_per_group |
Optional[int] |
For ranking projects and when |
None |
Returns:
| Type | Description |
|---|---|
pd.DataFrame |
The QIIs/shapley-values associated with the current data-split. |
get_feature_names(self)
inherited
¶
Get the feature names associated with the current data-collection.
Returns:
| Type | Description |
|---|---|
Sequence[str] |
Feature names. |
get_influence_type(self)
¶
Get the influence algorithm type of the currently set project.
get_influences_background_data_split(self, data_collection_name=None)
¶
Get the background data split used for computing feature influences.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
data_collection_name |
Optional[str] |
(Optional) Name of the data collection. Defaults to the current data collection in context. |
None |
Returns:
| Type | Description |
|---|---|
str |
Name of the background data split. |
get_ingestion_client(self)
¶
[Alpha] Get the data ingestion client associated with the TruEra workspace. Valid only for "remote" workspace. The ingestion client can be used to pull data from different data sources into TruEra to perform analytics.
Exceptions:
| Type | Description |
|---|---|
ValueError |
Raised if no project is associated with the current workspace. Use set_project to set the correct project. |
ValueError |
Raised if no data collection is associated with the current workspace. Use set_data_collection to set the correct data collection. |
ValueError |
Raised if the current project is a local project. |
Returns:
| Type | Description |
|---|---|
IngestionClient |
IngestionClient for current context of the TruEra workspace. |
get_ingestion_operation_status(self, *, operation_id=None, idempotency_id=None)
¶
Retrieve ingestion operation status by providing either the operation id or the idempotency id.
In the case an idempotency id which is associated with no operation id is used, a NotFoundError is raised,
which means this idempotency id is not used before.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
operation_id |
Optional[str] |
Defaults to None. |
None |
idempotency_id |
Optional[str] |
Defaults to None. |
None |
Returns:
| Type | Description |
|---|---|
dict |
Contains project_name, operation_started_time, operation_status, operation_id, split_id. |
get_maximum_model_runner_failure_rate(self)
¶
Get the maximum model runner failure rate (fraction of points on which the model can fail for a model run to be considered successful) for the current project.
get_model_metadata(self)
¶
Get model metadata for the current model in context.
get_model_threshold(self)
¶
Gets the model threshold for the currently set model and score type in the TruEra workspace.
Returns:
| Type | Description |
|---|---|
Optional[float] |
The model threshold. |
get_models(self)
¶
Get all models in the connected project.
Exceptions:
| Type | Description |
|---|---|
ValueError |
Raised if the workspace isn't connected to any project. |
Returns:
| Type | Description |
|---|---|
Sequence[str] |
Name of models in the project. |
get_nn_user_configs(self)
¶
Get NN user configurations for project and model set in the current context.
Examples:
>>> from truera.client.nn.client_configs import NLPAttributionConfiguration
>>> attr_config = NLPAttributionConfiguration(
>>> token_embeddings_layer=token_embeddings_layer_name,
>>> token_embeddings_anchor=token_embeddings_layer_tensor_anchor,
>>> n_output_neurons=n_output_neurons,
>>> n_metrics_records=n_metrics_records,
>>> rebatch_size=rebatch_size,)
# View the ingested config after add_nn_model in NN Ingestion...
>>> tru.get_nn_user_configs()
Returns:
| Type | Description |
|---|---|
Union[AttributionConfiguration, RNNUserInterfaceConfiguration] |
NN user config. |
get_num_default_influences(self)
¶
Get the number of influences computed by default of the currently set project.
Returns:
| Type | Description |
|---|---|
int |
Number of default influences. |
get_num_internal_qii_samples(self)
¶
Get the number of samples used internally in influence computations of the currently set project.
Returns:
| Type | Description |
|---|---|
int |
Number of samples to be used internally for influence computations. |
get_predictions(self, start=0, stop=None, system_data=False, by_group=False, num_per_group=None)
¶
Get the model predictions associated with the current data-split. Note that, if you set the start and stop, the number of records returned will not be the exact number requested but in the neighborhood of the start and stop limit provided.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
start |
Optional[int] |
The lower bound (inclusive) of the index of points to include. Defaults to 0. |
0 |
stop |
Optional[int] |
The upper bound (exclusive) of the index of points to include. Defaults to None which is interpreted as the total number of points for local projects and the setting for "Number of default influences" for remote projects. |
None |
system_data |
bool |
Include system data (e.g. timestamps) if available in response. Defaults to False. |
False |
by_group |
bool |
For ranking projects, whether to retrieve data by group or not. Ignored for non-ranking projects. Defaults to False. |
False |
num_per_group |
Optional[int] |
For ranking projects and when |
None |
Returns:
| Type | Description |
|---|---|
pd.DataFrame |
The model predictions associated with the current data-split. |
get_projects(self)
¶
Get all projects accessible by current user for the current workspace environment.
get_ranking_k(self)
¶
Gets the ranking k for the current project.
Returns:
| Type | Description |
|---|---|
int |
Ranking k. |
get_scheduled_ingestion(self, workflow_id)
¶
[Alpha] Get the metadata about a scheduled ingestion from a workflow_id
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
workflow_id |
str |
The id of the scheduled ingestion workflow. |
required |
Returns:
| Type | Description |
|---|---|
GetScheduleResponse |
Returns an object containing the request_template, schedule, and run_results of a workflow. |
get_segment_groups(self)
¶
[Alpha] Get all segment groups associated with the current TruEra workspace, along with their respective segments.
Returns:
| Type | Description |
|---|---|
Mapping[str, Mapping[str, str]] |
Mapping of segment group names to the corresponding segment group definition. |
get_xs(self, start=0, stop=None, extra_data=False, system_data=False, by_group=False, num_per_group=None)
¶
Get the inputs/data/x-values associated with the current data-split. Note that, if you set the start and stop, the number of records returned will not be the exact number requested but in the neighborhood of the start and stop limit provided.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
start |
Optional[int] |
The lower bound (inclusive) of the index of points to include. Defaults to 0. |
0 |
stop |
Optional[int] |
The upper bound (exclusive) of the index of points to include. Defaults to None which is interpreted as the total number of points for local projects and the setting for "Number of default influences" for remote projects. |
None |
extra_data |
bool |
Include extra data columns in the response. Defaults to False. |
False |
system_data |
bool |
Include system data (e.g. timestamps) if available in response. Defaults to False. |
False |
by_group |
bool |
For ranking projects, whether to retrieve data by group or not. Ignored for non-ranking projects. Defaults to False. |
False |
num_per_group |
Optional[int] |
For ranking projects and when |
None |
Returns:
| Type | Description |
|---|---|
pd.DataFrame |
The inputs/data/x-values associated with the current data-split. |
get_ys(self, start=0, stop=None, system_data=False, by_group=False, num_per_group=None)
¶
Get the targets/y-values associated with the current data-split. Note that, if you set the start and stop, the number of records returned will not be the exact number requested but in the neighborhood of the start and stop limit provided.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
start |
Optional[int] |
The lower bound (inclusive) of the index of points to include. Defaults to 0. |
0 |
stop |
Optional[int] |
The upper bound (exclusive) of the index of points to include. Defaults to None which is interpreted as the total number of points for local projects and the setting for "Number of default influences" for remote projects. |
None |
system_data |
bool |
Include system data (e.g. timestamps) if available in response. Defaults to False. |
False |
by_group |
bool |
For ranking projects, whether to retrieve data by group or not. Ignored for non-ranking projects. Defaults to False. |
False |
num_per_group |
Optional[int] |
For ranking projects and when |
None |
Returns:
| Type | Description |
|---|---|
pd.DataFrame |
The targets/y-values associated with the current data-split. |
get_ys_pred(self, start=0, stop=None, system_data=False, by_group=False, num_per_group=None, wait=True)
¶
Get the model predictions associated with the current data-split. Note that, if you set the start and stop, the number of records returned will not be the exact number requested but in the neighborhood of the start and stop limit provided.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
start |
Optional[int] |
The lower bound (inclusive) of the index of points to include. Defaults to 0. |
0 |
stop |
Optional[int] |
The upper bound (exclusive) of the index of points to include. Defaults to None which is interpreted as the total number of points for local projects and the setting for "Number of default influences" for remote projects. |
None |
system_data |
bool |
Include system data (e.g. timestamps) if available in response. Defaults to False. |
False |
by_group |
bool |
For ranking projects, whether to retrieve data by group or not. Ignored for non-ranking projects. Defaults to False. |
False |
num_per_group |
Optional[int] |
For ranking projects and when |
None |
wait |
bool |
Whether to wait for the job to finish. Defaults to True. |
True |
Returns:
| Type | Description |
|---|---|
pd.DataFrame |
The model predictions associated with the current data-split. |
ingest_events(self, events, project_name=None, model_name=None, raise_errors=True)
¶
Ingest events for production monitoring.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
events |
Sequence[Mapping[str, Any]] |
A sequence of events, where each event is a mapping of column name to value |
required |
project_name |
Optional[str] |
The name of the project to ingest into. Defaults to project in context. |
None |
raise_errors |
bool |
Whether to raise errors encountered during ingestion. Defaults to True. |
True |
Returns:
| Type | Description |
|---|---|
cf.Future[StreamingResponse] |
cf.Future[StreamingResponse] |
Exceptions:
| Type | Description |
|---|---|
StreamingValidationErrorGroup |
Raised if |
Examples:
>>> f = tru.ingest_events(
events=[
{
"id": "id_of_event",
"timestamp": "2024-02-01T21:17:34+00:00",
"my_float": 1.2,
"my_bool": True,
"my_string": "string_value",
"my_label": 1,
...
},
{...},
{...}
],
raise_errors=False # Handle errors in a callback instead
)
>>> f.add_done_callback(
lambda f: [print(err) for err in f.result().errors]
)
list_monitoring_tables(self)
¶
lists monitoring tables relevant to current project
Returns:
| Type | Description |
|---|---|
str |
Returns a json of objects containing the monitoring tables for a project |
list_performance_metrics(self)
¶
Lists the available metrics that can be supplied to compute performance, and be set as the project default.
Returns:
| Type | Description |
|---|---|
Sequence[str] |
Available metrics. |
list_scheduled_ingestions(self, last_key=None, limit=50)
¶
[Alpha] List workflows.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
last_key |
str |
The last id to fetch workflows after. Defaults to None. |
None |
limit |
int |
The number of workflows to fetch. Defaults to 50. |
50 |
Returns:
| Type | Description |
|---|---|
str |
Returns a list of objects containing the workflow_id and active state of all workflows. |
list_valid_score_types(self)
inherited
¶
List the valid score types that can be set for the currently set project.
Returns:
| Type | Description |
|---|---|
Sequence[str] |
Valid score types. |
schedule_existing_data_split(self, split_name, cron_schedule, override_split_name=None, append=True)
¶
[Alpha] Schedule a new scheduled ingestion based off an existing split.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
split_name |
str |
The name of an already materialized split. |
required |
cron_schedule |
str |
The schedule for the periodic ingestion. Follows cron unix format: ┌───────────── minute (0 - 59) │ ┌───────────── hour (0 - 23) │ │ ┌───────────── day of the month (1 - 31) │ │ │ ┌───────────── month (1 - 12) │ │ │ │ ┌───────────── day of the week (0 - 6) (Sunday to Saturday; │ │ │ │ │ 7 is also Sunday on some systems) │ │ │ │ │ │ │ │ │ │ For example, to run a cron on the first of every month: "0 0 1 * *" |
required |
override_split_name |
str |
The name of the new splits to be created. For information on templating, see the schedule_ingestion function. |
None |
Returns:
| Type | Description |
|---|---|
str |
A workflow_id for looking up the workflow. |
schedule_ingestion(self, raw_json, cron_schedule)
¶
[Alpha] Schedule a new scheduled ingestion based off a JSON request tree.
Templating
Templating is supported for uris, split names, and filter expessions for scheduled
ingestion. The scheduler passes in several variables and functions when evaluating the
supported field, which can be accessed by using the syntax: ${
For example, to add the run date to the split name you can add the following suffix when submitting a split name to scheduled ingestion: "split_name_${formatDate("yyyy-MM-dd", now)}"
Supported variables: - now: The Date of the run. - last: The Date of the last run. - lastSuccess: The Date of the last successful run.
Supported functions:
- uuid(): Generate a random v4 uuid.
- formatDate(
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
raw_json |
str |
The JSON string representation of the request tree. To build a json string, you can use the serialize_split function. |
required |
cron_schedule |
str |
The schedule for the periodic ingestion. Follows cron unix format: ┌───────────── minute (0 - 59) │ ┌───────────── hour (0 - 23) │ │ ┌───────────── day of the month (1 - 31) │ │ │ ┌───────────── month (1 - 12) │ │ │ │ ┌───────────── day of the week (0 - 6) (Sunday to Saturday; │ │ │ │ │ 7 is also Sunday on some systems) │ │ │ │ │ │ │ │ │ │ For example, to run a cron on the first of every month: "0 0 1 * *" |
required |
Returns:
| Type | Description |
|---|---|
str |
A workflow_id for looking up the workflow. |
serialize_split(self, split_name, override_split_name=None)
¶
[Alpha] Build a request tree represented as a JSON string.
Templating
Templating is supported for uris, split names, and filter expressions for scheduled
ingestion. The scheduler passes in several variables and functions when evaluating the
supported field, which can be accessed by using the syntax: ${
For example, to add the run date to the split name you can add the following suffix when submitting a split name to scheduled ingestion: "split_name_${formatDate("yyyy-MM-dd", now)}"
Supported variables: - now: The Date of the run. - last: The Date of the last run. - lastSuccess: The Date of the last successful run.
Supported functions:
- uuid(): Generate a random v4 uuid.
- formatDate(
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
split_name |
str |
The name of an already materialized split. |
required |
override_split_name |
str |
The optional name to replace the original split name. For information on templating, see the schedule_ingestion function. |
None |
Returns:
| Type | Description |
|---|---|
str |
A JSON string representing the request tree that can be used for scheduled ingestion. |
set_as_protected_segment(self, segment_group_name, segment_name)
¶
Sets the provided segment as a "protected" segment. This enables fairness analysis for this segment.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
segment_group_name |
Name of segment group. |
required | |
segment_name |
str |
Name of segment in provided segment group. |
required |
Examples:
>>> tru.set_project("Project Name")
>>> tru.set_data_collection("Data Collection Name")
# Add a segment group for Sex
>>> tru.add_segment_group(name = "Sex", segment_definitions = {"Male": "Sex == 'Male'", "Female": "Sex == 'Female'"})
# Set the Female Segment as a Protected Segment
>>> tru.set_as_protected_segment(segment_group_name = "Sex", segment_name = "Female")
set_data_collection(self, data_collection_name)
¶
Set the current data collection to use for all operations in the workspace. This will also unset the current model if it is not associated with the provided data collection.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
data_collection_name |
str |
Name of the data_collection. If None, will unset the data collection. |
required |
Exceptions:
| Type | Description |
|---|---|
ValueError |
Raised if no project is associated with the current workspace. Use set_project to set the correct project. |
ValueError |
Raised if there is no such data_collection in the project. |
set_data_split(self, data_split_name)
¶
Set the current data split to use for all operations in the current workspace.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
data_split_name |
str |
Name of the data_split. If None, will unset the data split. |
required |
Exceptions:
| Type | Description |
|---|---|
ValueError |
Raised if no project is associated with the current workspace. Use set_project to set the correct project. |
ValueError |
Raised if no data_collection is associated with the current workspace. Use set_data_collection to set the correct data_collection. |
ValueError |
Raised if there is no such data_split in the data_collection. |
set_default_performance_metrics(self, performance_metrics)
¶
Set the default performance metrics of the currently set project.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
performance_metrics |
Sequence[str] |
Performance metrics to use by default. |
required |
set_influence_type(self, algorithm)
¶
Set the influence algorithm type of the currently set project.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
algorithm |
str |
Algorithm type. Options are ["truera-qii", "shap"]. Defaults to "truera-qii" if available, and otherwise "shap". |
required |
set_influences_background_data_split(self, data_split_name, data_collection_name=None)
¶
Set the background data split used for computing feature influences.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
data_split_name |
str |
Name of the data split. |
required |
data_collection_name |
Optional[str] |
(Optional) Name of the data collection. Defaults to the current data collection in context. |
None |
set_maximum_model_runner_failure_rate(self, maximum_model_runner_failure_rate)
¶
Sets the maximum model runner failure rate (fraction of points on which the model can fail for a model run to be considered successful) for the current project.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
maximum_model_runner_failure_rate |
float |
Maximum failure rate. Must be in [0, 1). By default, it is set to 0. |
required |
set_model(self, model_name)
¶
Set the current model to use for all operations in the current workspace. This will also change the data collection to the one corresponding to the provided model if different than the priorly set data collection.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
model_name |
str |
Name of the model. If None, will unset the model. |
required |
Exceptions:
| Type | Description |
|---|---|
ValueError |
Raised if no project is associated with the current workspace. Use set_project to set the correct project. |
ValueError |
Raised if there is no such model in the project. |
set_model_execution(self, environment)
¶
Set the environment (either local or remote) to execute models in.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
environment |
str |
Environment to execute models in. Either "local" or "remote". |
required |
set_num_default_influences(self, num_default_influences)
¶
Set the number of influences computed by default of the currently set project.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
num_default_influences |
int |
Number of influences used by default for most influence-requiring graphs, computations, etc. Note that this will take the first of the provided many from the data split --- therefore, shuffling data splits is generally advised prior to ingestion. |
required |
set_num_internal_qii_samples(self, num_samples)
¶
Set the number of samples used internally in influence computations of the currently set project.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
num_samples |
int |
Number of samples to be used internally for influence computations. |
required |
set_project(self, project)
¶
Set the current project to use for the current workspace environment. This will unset the rest of the context (data collection, data split, model, etc.) if set prior.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
project |
str |
Name of the project. |
required |
Exceptions:
| Type | Description |
|---|---|
ValueError |
Raised if the project does not exist. |
set_ranking_k(self, ranking_k)
¶
Sets the ranking k for the current project.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
ranking_k |
int |
Must be in >= 0. |
required |
set_score_type(self, score_type)
¶
Set the score type of the currently set project.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
score_type |
str |
Scorer type configuration. Options are ["logits", "probits", "classification", "regression", None]. Defaults to None. |
required |
update_model_threshold(self, classification_threshold)
¶
Update the classification threshold for the model associated with the TruEra workspace. A model score (probits, logits) that is greater than or equal to the threshold is assigned a positive classification outcome.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
classification_threshold |
float |
New threshold to update. Ignored for regression models. |
required |
update_nn_user_config(self, config)
¶
Update NN user configurations for project and model set in the current context.
Examples:
# If you need to make changes to the attributions config after you have run add_nn_model in NN Ingestion...
>>> from truera.client.nn.client_configs import NLPAttributionConfiguration
>>> updated_attr_config = NLPAttributionConfiguration(
>>> token_embeddings_layer=token_embeddings_layer_name,
>>> token_embeddings_anchor=token_embeddings_layer_tensor_anchor,
>>> n_output_neurons=n_output_neurons,
>>> n_metrics_records=n_metrics_records,
>>> rebatch_size=rebatch_size,
>>> )
>>> tru.update_nn_user_config(updated_attr_config)
>>> tru.get_nn_user_configs() # Will return the updated attr_config
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
config |
Union[AttributionConfiguration, RNNUserInterfaceConfiguration] |
Config to set. |
required |
verify_nn_wrappers(self, *, clf, attr_config=None, truera_wrappers)
¶
Validates that all wrappers and methods are well formed.
Examples:
# During NN Ingestion you will create two objects
>>> from truera.client.nn.client_configs import NLPAttributionConfiguration
>>> attr_config = NLPAttributionConfiguration(...)
>>> from truera.client.nn.wrappers.autowrap import autowrap
>>> truera_wrappers = autowrap(...) # Use the appropriate NN Diagnostics Ingestion to create this
# Check if ingestion is set up correctly
>>> tru.verify_nn_wrappers(
>>> clf=model,
>>> attr_config=attr_config,
>>> truera_wrappers=truera_wrappers
>>> )
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
clf |
NNBackend.Model |
The model object. |
required |
truera_wrappers |
Optional[base.WrapperCollection] |
A collection of wrappers |
required |
verify_packaged_model(self, model_path)
¶
Locally verifies a packaged Python model by loading the model and, if available, running it on split data ingested into the TruEra system.
The model must already be packaged, e.g. via create_packaged_python_model(). The project and data collection for the model must also be set in the current workspace context.
This function assumes that it is running an environment with any model dependencies/packages installed.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
model_path |
str |
Path to packaged model directory. |
required |
BasicAuthentication (TrueraAuthentication)
¶
Basic authentication for BaseTrueraWorkspace.
__init__(self, username, password)
special
¶
Construct BasicAuth for BaseTrueraWorkspace.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
username |
str |
Username for the basic auth credentials. |
required |
password |
str |
Password for the basic auth credentials. |
required |
Note: Most users will use TokenAuthentication rather than BasicAuthentication.
Examples:
# import BasicAuthentication and TruEraWorkspace
>>> from truera.client.truera_authentication import BasicAuthentication
>>> from truera.client.truera_workspace import TrueraWorkspace
# Create authentication object
>>> auth = BasicAuthentication(username="My Username", password="My Password")
# Create TruEra Workspace
>>> tru = TrueraWorkspace(connection_string="https://myconnectionstring", authentication=auth)
ServiceAccountAuthentication (TrueraAuthentication)
¶
Service Account Authentication for BaseTrueraWorkspace.
__init__(self, client_id, client_secret, *, token_endpoint=None, additional_payload=None, verify_cert=True)
special
¶
Construct ServiceAccountAuth for BaseTrueraWorkspace.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
client_id |
str |
Client ID from service account credentials. |
required |
client_secret |
str |
Client secret from service account credentials. |
required |
token_endpoint |
Optional[str] |
Optional override of the endpoint to retrieve token from. |
None |
additional_payload |
Optional[Mapping[str, str]] |
Optional payload to include in request to retrieve token. |
None |
set_token_endpoint(self, endpoint, append_path=True, overwrite=False)
¶
Set token endpoint. Appends '/oauth/token' to endpoint if append_path is True. Does nothing if token_endpoint is already defined unless overwrite is True.
TokenAuthentication (TrueraAuthentication)
¶
Token authentication for BaseTrueraWorkspace.
__init__(self, token)
special
¶
Construct TokenAuth for BaseTrueraWorkspace.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
token |
str |
Token containing credentials to authenticate with the services. |
required |
Note: Most users will use TokenAuthentication rather than BasicAuthentication.
Examples:
# import TokenAuthentication and TruEraWorkspace
>>> from truera.client.truera_authentication import TokenAuthentication
>>> from truera.client.truera_workspace import TrueraWorkspace
# Create authentication object
>>> auth = TokenAuthentication(token="My Token From the TruEra Web App")
# Create TruEra Workspace
>>> tru = TrueraWorkspace(connection_string="https://myconnectionstring", authentication=auth)
Explainer (ABC)
¶
clear_segment(self)
¶
Clears any set segments from all explainer operations.
Examples:
# Assuming `tru` is a `TrueraWorkspace`.
>>> explainer = tru.get_explainer("split1")
>>> explainer.set_segment("segment_group1", "segment1_in_segment_group1")
# This will return only the xs in "split1" filtered to the segment "segment1_in_segment_group1".
>>> explainer.get_xs()
>>> explainer.clear_segment()
# This will return all the xs in "split1".
>>> explainer.get_xs()
compute_feature_influences(self, start=0, stop=None, score_type=None, system_data=False, by_group=False, num_per_group=None, wait=True)
¶
Compute the QIIs/shapley-values for this explainer's currently set data split.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
start |
Optional[int] |
The lower bound (inclusive) of the index of points to include. Defaults to 0. |
0 |
stop |
Optional[int] |
The upper bound (exclusive) of the index of points to include. Defaults to None which is interpreted as the project setting for "Number of default influences". |
None |
score_type |
Optional[str] |
The score type to use when computing influences. If None, defaults to score type of project. Defaults to None. For a list of valid score types, see |
None |
system_data |
bool |
Include system data (e.g. timestamps) if available in response. Defaults to False. |
False |
wait |
bool |
Whether to wait for the job to finish. Defaults to True. |
True |
Returns:
| Type | Description |
|---|---|
pd.DataFrame |
The QIIs/shapley-values. |
Examples:
# Assuming `tru` is a `TrueraWorkspace`.
>>> tru.set_model("model1")
>>> explainer = tru.get_explainer("split1")
# This will return "model1"'s feature influences on "split1".
>>> explainer.compute_feature_influences()
compute_feature_influences_for_data(self, pre_data, post_data=None, ys=None, score_type=None, comparison_post_data=None, num_internal_qii_samples=1000, algorithm='truera-qii')
¶
Compute the QIIs/shapley-values for the provided data.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
pre_data |
pd.DataFrame |
A pandas DataFrame containing the human-readable data for which to compute influences. If |
required |
post_data |
Optional[pd.DataFrame] |
A pandas DataFrame containing the model-readable post-processed data that is aligned with the pre-processed data. Can be ignored if model-readable pre-processed data is provided. If providing different pre- and post-processed data, be sure the mapping between them adheres to the feature map of the data collection specified during the data collection's creation. |
None |
ys |
Optional[Union[np.ndarray, pd.Series]] |
Labels for which to compute influences if required by the provided |
None |
score_type |
Optional[str] |
The score type to use when computing influences. If None, defaults to score type of project. Defaults to None. For a list of valid score types, see |
None |
comparison_post_data |
Optional[pd.DataFrame] |
The comparison data to use when computing influences. If None, defaults to a data split of the data collection of type "all" or "train" and failing that uses the base split currently set in this explainer. Defaults to None. |
None |
num_internal_qii_samples |
int |
Number of samples used internally in influence computations. |
1000 |
algorithm |
str |
Algorithm to use during computation. Must be one of ["truera-qii", "tree-shap-tree-path-dependent", "tree-shap-interventional", "kernel-shap"]. Defaults to "truera-qii". |
'truera-qii' |
Returns:
| Type | Description |
|---|---|
pd.DataFrame |
The QIIs/shapley-values. |
Examples:
# Assuming `tru` is a `TrueraWorkspace`.
>>> tru.set_model("model1")
>>> explainer = tru.get_explainer("split1")
>>> pre_data = ...
>>> post_data = ...
# This will compute feature influences on `pre_data`/`post_data`. Note that the feature mapping from
# `pre_data` to `post_data` must be the same as that expected by "model1".
>>> explainer.compute_feature_influences_for_data(
pre_data=pre_data,
post_data=post_data,
score_type="probits",
comparison_post_data=post_data
)
compute_performance(self)
¶
Computes performance metrics from labels and predictions. To see the list of available metrics, use list_performance_metrics
Examples:
# Set your project, data collection and model
>>> tru.set_project("Project Name")
>>> tru.set_data_collection("data collection name")
>>> tru.set_model("model v1")
# Get the explainer for the base split
>>> explainer = tru.get_explainer("train split name")
# Compute performance for the base split using the explainer object
>>> explainer.compute_performance(metric_type = "MAE", plot = False)
get_base_data_split(self)
¶
Get the base data split used by explainer.
Returns:
| Type | Description |
|---|---|
str |
The name of the base data split. |
get_comparison_data_splits(self)
¶
Gets the comparison data splits used by the explainer.
Returns:
| Type | Description |
|---|---|
Sequence[str] |
The names of the comparison data splits. |
get_data_collection(self)
¶
Get the data collection name used by explainer.
get_feature_names(self)
¶
Get the feature names associated with the current data-collection.
Returns:
| Type | Description |
|---|---|
Sequence[str] |
Feature names. |
get_spline_fitter(self, start=0, stop=None)
¶
Get the spline-fitter using the provided range of points to fit splines.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
start |
int |
The lower bound (inclusive) of the index of points to use during spline fitting. Defaults to 0. |
0 |
stop |
Optional[int] |
The upper bound (exclusive) of the index of points to use during spline fitting. Defaults to the number of Number of default influences for the project. |
None |
Returns:
| Type | Description |
|---|---|
SplineFitter |
Spline-fitter. |
Examples:
# Assuming `tru` is a `TrueraWorkspace`.
tru.set_model("model1")
explainer = tru.get_explainer("split1")
# Construct a spline fitter and use it to construct a GAM.
sf = explainer.get_spline_fitter("segment_group1", "segment1_in_segment_group1")
gam = sf.construct_gam(
n_splines=10,
spline_orders=3,
constraints={"feature2": "monotonic_inc", "feature5": "monotonic_dec"}
)
# Add GAM model into TruEra.
tru.add_python_model("GAM from model1", gam)
get_xs(self, start=0, stop=None, extra_data=False, system_data=False, by_group=False, num_per_group=None)
¶
Get the inputs/data/x-values.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
start |
Optional[int] |
The lower bound (inclusive) of the index of points to include. Defaults to 0. |
0 |
stop |
Optional[int] |
The upper bound (exclusive) of the index of points to include. Defaults to None which is interpreted as the total number of points for local projects and the setting for "Number of default influences" for remote projects. |
None |
extra_data |
bool |
Include extra data columns in the response. |
False |
system_data |
bool |
Include system data columns (unique ID) in the response. |
False |
by_group |
bool |
For ranking projects, whether to retrieve data by group or not. Ignored for non-ranking projects. Defaults to False. |
False |
num_per_group |
Optional[int] |
For ranking projects and when |
None |
Returns:
| Type | Description |
|---|---|
pd.DataFrame |
The inputs/data/x-values. |
get_ys(self, start=0, stop=None, system_data=False, by_group=False, num_per_group=None)
¶
Get the targets/y-values.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
start |
Optional[int] |
The lower bound (inclusive) of the index of points to include. Defaults to 0. |
0 |
stop |
Optional[int] |
The upper bound (exclusive) of the index of points to include. Defaults to None which is interpreted as the total number of points for local projects and the setting for "Number of default influences" for remote projects. |
None |
system_data |
bool |
Include system data columns (unique ID) in the response. |
False |
by_group |
bool |
For ranking projects, whether to retrieve data by group or not. Ignored for non-ranking projects. Defaults to False. |
False |
num_per_group |
Optional[int] |
For ranking projects and when |
None |
Returns:
| Type | Description |
|---|---|
pd.DataFrame |
The targets/y-values as a pd.DataFrame. |
get_ys_pred(self, start=0, stop=None, system_data=False, by_group=False, num_per_group=None, wait=True)
¶
Get the model predictions.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
start |
Optional[int] |
The lower bound (inclusive) of the index of points to include. Defaults to 0. |
0 |
stop |
Optional[int] |
The upper bound (exclusive) of the index of points to include. Defaults to None which is interpreted as the total number of points for local projects and the setting for "Number of default influences" for remote projects. |
None |
system_data |
bool |
Include system data (e.g. timestamps) if available in response. Defaults to False. |
False |
by_group |
bool |
For ranking projects, whether to retrieve data by group or not. Ignored for non-ranking projects. Defaults to False. |
False |
num_per_group |
Optional[int] |
For ranking projects and when |
None |
wait |
bool |
Whether to wait for the job to finish. Defaults to True. |
True |
Returns:
| Type | Description |
|---|---|
pd.DataFrame |
The model predictions as a pd.DataFrame. |
Examples:
# Assuming `tru` is a `TrueraWorkspace`.
>>> tru.set_model("model1")
>>> explainer = tru.get_explainer("split1")
# This will return "model1"'s predictions on "split1".
>>> explainer.get_ys_pred()
list_performance_metrics(self)
¶
Lists the available metrics that can be supplied to compute_performance.
set_base_data_split(self, data_split_name=None)
¶
Set the base data split to use for all operations in the explainer.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
data_split_name |
Optional[str] |
Name of the data split. |
None |
Examples:
# Assuming `tru` is a `TrueraWorkspace`.
>>> explainer = tru.get_explainer("split1")
# Gets labels for data-split "split1".
>>> explainer.get_ys()
>>> explainer.set_base_data_split("split2")
# Gets labels for data-split "split2".
>>> explainer.get_ys()
set_comparison_data_splits(self, comparison_data_splits=None, use_all_data_splits=False)
¶
Sets comparison data splits to use for all operations in the explainer.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
comparison_data_splits |
Optional[Sequence[str]] |
List of data split names for comparison. This is ignored if |
None |
use_all_data_splits |
bool |
If set to True, set comparison data splits as all of the data splits in the data collection except the base data split. (Optional) |
False |
Examples:
# Assuming `tru` is a `TrueraWorkspace`.
>>> explainer = tru.get_explainer("split1")
>>> explainer = tru.set_comparison_data_splits(["split2", "split3"])
# This will compute AUC metrics for "split1" and compare to "split2" and "split3".
>>> explainer.compute_performance("AUC")
set_segment(self, segment_group_name, segment_name)
¶
Sets and applies a segment filter to all explainer operations.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
segment_group_name |
str |
Name of segment group under which the segment is defined. |
required |
segment_name |
str |
Name of the segment. |
required |
Examples:
# Assuming `tru` is a `TrueraWorkspace`.
>>> explainer = tru.get_explainer("split1")
# This will return all the xs in "split1".
>>> explainer.get_xs()
>>> explainer.set_segment("segment_group1", "segment1_in_segment_group1")
# This will return only the xs in "split1" filtered to the segment "segment1_in_segment_group1".
>>> explainer.get_xs()
NonTabularExplainer (Explainer)
¶
clear_segment(self)
¶
Not Available for NonTabularExplainer
compute_feature_influences(self, start=0, stop=None, system_data=False, by_group=False, num_per_group=None, wait=True)
¶
Gets the input influences.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
- |
start (int |
A starting offset of the data records |
required |
- |
stop (int |
A stop offset of the data records |
required |
Examples:
# During NN Ingestion you will create two objects
>>> from truera.client.nn.client_configs import NLPAttributionConfiguration
>>> attr_config = NLPAttributionConfiguration(...)
>>> from truera.client.nn.wrappers.autowrap import autowrap
>>> truera_wrappers = autowrap(...) # Use the appropriate NN Diagnostics Ingestion to create this
# Check if ingestion is set up correctly
>>> tru.verify_nn_wrappers(
clf=model,
attr_config=attr_config,
truera_wrappers=truera_wrappers
)
# Add the model and data to the truera workspace
>>> tru.add_nn_model(
model_name="<model_name>",
truera_wrappers,
attr_config
)
>>> tru.add_nn_data_split(
data_split_name="<split_name>",
truera_wrappers,
split_type="<split_type_train_or_test>"
)
# Compute influences
>>> tru.compute_feature_influences()
compute_feature_influences_for_data(self)
¶
Not Available for NonTabularExplainer
compute_performance(self)
inherited
¶
Computes performance metrics from labels and predictions. To see the list of available metrics, use list_performance_metrics
Examples:
# Set your project, data collection and model
>>> tru.set_project("Project Name")
>>> tru.set_data_collection("data collection name")
>>> tru.set_model("model v1")
# Get the explainer for the base split
>>> explainer = tru.get_explainer("train split name")
# Compute performance for the base split using the explainer object
>>> explainer.compute_performance(metric_type = "MAE", plot = False)
get_base_data_split(self)
¶
Not Available for NonTabularExplainer
get_comparison_data_splits(self)
¶
Not Available for NonTabularExplainer
get_data_collection(self)
inherited
¶
Get the data collection name used by explainer.
get_feature_names(self)
inherited
¶
Get the feature names associated with the current data-collection.
Returns:
| Type | Description |
|---|---|
Sequence[str] |
Feature names. |
get_spline_fitter(self, start=0, stop=None)
¶
Not Available for NonTabularExplainer
get_xs(self, start=0, stop=None, extra_data=False, system_data=False, by_group=False, num_per_group=None)
inherited
¶
Get the inputs/data/x-values.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
start |
Optional[int] |
The lower bound (inclusive) of the index of points to include. Defaults to 0. |
0 |
stop |
Optional[int] |
The upper bound (exclusive) of the index of points to include. Defaults to None which is interpreted as the total number of points for local projects and the setting for "Number of default influences" for remote projects. |
None |
extra_data |
bool |
Include extra data columns in the response. |
False |
system_data |
bool |
Include system data columns (unique ID) in the response. |
False |
by_group |
bool |
For ranking projects, whether to retrieve data by group or not. Ignored for non-ranking projects. Defaults to False. |
False |
num_per_group |
Optional[int] |
For ranking projects and when |
None |
Returns:
| Type | Description |
|---|---|
pd.DataFrame |
The inputs/data/x-values. |
get_ys(self, start=0, stop=None, system_data=False, by_group=False, num_per_group=None)
inherited
¶
Get the targets/y-values.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
start |
Optional[int] |
The lower bound (inclusive) of the index of points to include. Defaults to 0. |
0 |
stop |
Optional[int] |
The upper bound (exclusive) of the index of points to include. Defaults to None which is interpreted as the total number of points for local projects and the setting for "Number of default influences" for remote projects. |
None |
system_data |
bool |
Include system data columns (unique ID) in the response. |
False |
by_group |
bool |
For ranking projects, whether to retrieve data by group or not. Ignored for non-ranking projects. Defaults to False. |
False |
num_per_group |
Optional[int] |
For ranking projects and when |
None |
Returns:
| Type | Description |
|---|---|
pd.DataFrame |
The targets/y-values as a pd.DataFrame. |
get_ys_pred(self, start=0, stop=None, system_data=False, by_group=False, num_per_group=None, wait=True)
inherited
¶
Get the model predictions.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
start |
Optional[int] |
The lower bound (inclusive) of the index of points to include. Defaults to 0. |
0 |
stop |
Optional[int] |
The upper bound (exclusive) of the index of points to include. Defaults to None which is interpreted as the total number of points for local projects and the setting for "Number of default influences" for remote projects. |
None |
system_data |
bool |
Include system data (e.g. timestamps) if available in response. Defaults to False. |
False |
by_group |
bool |
For ranking projects, whether to retrieve data by group or not. Ignored for non-ranking projects. Defaults to False. |
False |
num_per_group |
Optional[int] |
For ranking projects and when |
None |
wait |
bool |
Whether to wait for the job to finish. Defaults to True. |
True |
Returns:
| Type | Description |
|---|---|
pd.DataFrame |
The model predictions as a pd.DataFrame. |
Examples:
# Assuming `tru` is a `TrueraWorkspace`.
>>> tru.set_model("model1")
>>> explainer = tru.get_explainer("split1")
# This will return "model1"'s predictions on "split1".
>>> explainer.get_ys_pred()
list_performance_metrics(self)
inherited
¶
Lists the available metrics that can be supplied to compute_performance.
set_base_data_split(self, data_split_name=None)
¶
Not Available for NonTabularExplainer
set_comparison_data_splits(self)
¶
Not Available for NonTabularExplainer
set_segment(self, segment_group_name=None, segment_name=None)
¶
Not Available for NonTabularExplainer
TabularExplainer (Explainer)
¶
Contains methods to provide explanations for tabular models.
Examples:
# Assuming `tru` is a `TrueraWorkspace` with a tabular project
# Set your project, data collection and model
>>> tru.set_project("Project Name")
>>> tru.set_data_collection("data collection name")
>>> tru.set_model("model v1")
# Get the explainer for the base split
>>> explainer = tru.get_explainer("train split name")
clear_segment(self)
inherited
¶
Clears any set segments from all explainer operations.
Examples:
# Assuming `tru` is a `TrueraWorkspace`.
>>> explainer = tru.get_explainer("split1")
>>> explainer.set_segment("segment_group1", "segment1_in_segment_group1")
# This will return only the xs in "split1" filtered to the segment "segment1_in_segment_group1".
>>> explainer.get_xs()
>>> explainer.clear_segment()
# This will return all the xs in "split1".
>>> explainer.get_xs()
compute_fairness(self, segment_group, segment1, segment2=None, fairness_type='DISPARATE_IMPACT_RATIO', threshold=None, threshold_score_type=None)
¶
Compares the fairness of outcomes for two segments within a segment group using the provided fairness type.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
segment_group |
str |
Name of segment group that the two segments are defined under. |
required |
segment1 |
str |
Name of first segment (must belong to provided segment group). |
required |
segment2 |
Optional[str] |
Name of second segment (must belong to provided segment group). If None, then uses the complement of |
None |
fairness_type |
Optional[str] |
Name of fairness metric. Must be one of the options returned by |
'DISPARATE_IMPACT_RATIO' |
threshold |
Optional[float] |
Optional model threshold for classification models. If None, defaults to pre-configured threshold for the model. Ignored for regression models. |
None |
threshold_score_type |
Optional[str] |
If |
None |
Returns:
| Type | Description |
|---|---|
BiasResult |
Computed fairness metric along with information about which group is favored. |
Examples:
# Assuming `tru` is a `TrueraWorkspace`.
# Setup the project
>>> project_name = 'test_explainer_compute_fairness'
>>> tru.add_project(project_name, score_type='classification', input_type='tabular')
>>> tru.add_data_collection('dc')
# Create train data where membership 1 is unfairly treated
>>> wealth_max = 5000
>>> rng = np.random.default_rng(seed=42)
>>> wealth = rng.uniform(0.0,wealth_max,size=100)
>>> random_approvals = rng.binomial(1,0.25,size=50)
>>> xs_train = pd.DataFrame({
"membership": [0]*50 + [1]*50,
"wealth": wealth,
"approved": np.concatenate([[1]*50, random_approvals])
}).astype({
"membership": "int",
"wealth": "float",
"approved": "bool",
})
# Create data split.
>>> xs = xs_train.drop(['approved'], axis=1)
>>> labels = xs_train['approved']
>>> tru.add_data_split('train', pre_data = xs, label_data = labels, split_type = "train")
# Create xgb model
>>> import xgboost as xgb
>>> params = {"model_type": "xgb.XGBClassifier", "eta": 0.2, "max_depth": 4}
>>> xgb_clf = xgb.XGBClassifier(eta = params['eta'], max_depth = params['max_depth'])
>>> xgb_clf.fit(xs, labels)
# Add model to project and set model
>>> tru.add_python_model("xgb", xgb_clf, train_split_name="train", train_parameters=params)
>>> tru.set_model("xgb")
# Add a segment group on which to compute fairness
>>> tru.add_segment_group("membership", {"zero": 'membership == 0', 'one': 'membership == 1'})
# Compute fairness across gender and display results.
>>> explainer = tru.get_explainer("train")
>>> explainer.compute_fairness("membership", "one", "zero")
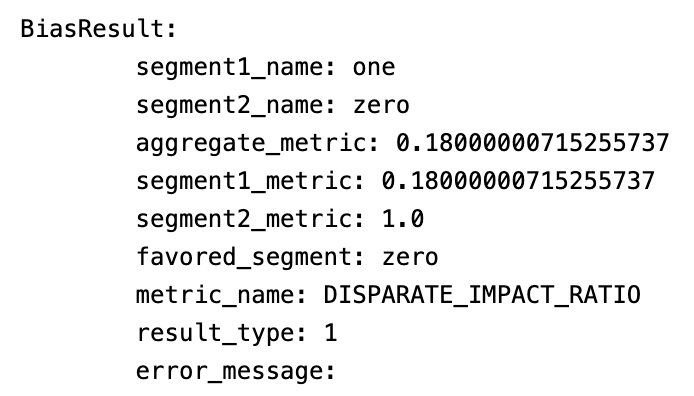
compute_feature_contributors_to_instability(self, score_type=None, use_difference_of_means=False, wait=True)
¶
Compute feature contributors to model instability from the base split to all comparison splits that are set in the current context. By default, instability is measured using Wasserstein Distance.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
score_type |
Optional[str] |
The score type to use when computing instability. If None, uses default score type of project. Defaults to None. For a list of valid score types, see |
None |
use_difference_of_means |
bool |
If True, measures instability with Difference of Means. Defaults to False. |
False |
wait |
bool |
Whether to wait for the job to finish. Defaults to True. |
True |
Returns:
| Type | Description |
|---|---|
pd.DataFrame |
Table of contributions per feature and comparison split. |
Examples:
# Assuming `tru` is a `TrueraWorkspace`.
>>> tru.set_model("model1")
>>> explainer = tru.get_explainer("split1")
# Add one or more comparison data split(s) to the current context.
>>> explainer.set_comparison_data_splits(["split2"])
# Show the features contributors to model instability for each comparison split.
>>> explainer.compute_feature_contributors_to_instability()
# Add multiple comparison data splits and re-run to see more output rows
>>> explainer.set_comparison_data_splits(["split2", "split3"])
>>> explainer.compute_feature_contributors_to_instability()
compute_feature_influences(self, start=0, stop=None, score_type=None, system_data=False, by_group=False, num_per_group=None, wait=True)
inherited
¶
Compute the QIIs/shapley-values for this explainer's currently set data split.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
start |
Optional[int] |
The lower bound (inclusive) of the index of points to include. Defaults to 0. |
0 |
stop |
Optional[int] |
The upper bound (exclusive) of the index of points to include. Defaults to None which is interpreted as the project setting for "Number of default influences". |
None |
score_type |
Optional[str] |
The score type to use when computing influences. If None, defaults to score type of project. Defaults to None. For a list of valid score types, see |
None |
system_data |
bool |
Include system data (e.g. timestamps) if available in response. Defaults to False. |
False |
wait |
bool |
Whether to wait for the job to finish. Defaults to True. |
True |
Returns:
| Type | Description |
|---|---|
pd.DataFrame |
The QIIs/shapley-values. |
Examples:
# Assuming `tru` is a `TrueraWorkspace`.
>>> tru.set_model("model1")
>>> explainer = tru.get_explainer("split1")
# This will return "model1"'s feature influences on "split1".
>>> explainer.compute_feature_influences()
compute_feature_influences_for_data(self, pre_data, post_data=None, ys=None, score_type=None, comparison_post_data=None, num_internal_qii_samples=1000, algorithm='truera-qii')
inherited
¶
Compute the QIIs/shapley-values for the provided data.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
pre_data |
pd.DataFrame |
A pandas DataFrame containing the human-readable data for which to compute influences. If |
required |
post_data |
Optional[pd.DataFrame] |
A pandas DataFrame containing the model-readable post-processed data that is aligned with the pre-processed data. Can be ignored if model-readable pre-processed data is provided. If providing different pre- and post-processed data, be sure the mapping between them adheres to the feature map of the data collection specified during the data collection's creation. |
None |
ys |
Optional[Union[np.ndarray, pd.Series]] |
Labels for which to compute influences if required by the provided |
None |
score_type |
Optional[str] |
The score type to use when computing influences. If None, defaults to score type of project. Defaults to None. For a list of valid score types, see |
None |
comparison_post_data |
Optional[pd.DataFrame] |
The comparison data to use when computing influences. If None, defaults to a data split of the data collection of type "all" or "train" and failing that uses the base split currently set in this explainer. Defaults to None. |
None |
num_internal_qii_samples |
int |
Number of samples used internally in influence computations. |
1000 |
algorithm |
str |
Algorithm to use during computation. Must be one of ["truera-qii", "tree-shap-tree-path-dependent", "tree-shap-interventional", "kernel-shap"]. Defaults to "truera-qii". |
'truera-qii' |
Returns:
| Type | Description |
|---|---|
pd.DataFrame |
The QIIs/shapley-values. |
Examples:
# Assuming `tru` is a `TrueraWorkspace`.
>>> tru.set_model("model1")
>>> explainer = tru.get_explainer("split1")
>>> pre_data = ...
>>> post_data = ...
# This will compute feature influences on `pre_data`/`post_data`. Note that the feature mapping from
# `pre_data` to `post_data` must be the same as that expected by "model1".
>>> explainer.compute_feature_influences_for_data(
pre_data=pre_data,
post_data=post_data,
score_type="probits",
comparison_post_data=post_data
)
compute_model_score_instability(self, score_type=None, use_difference_of_means=False, plot=False)
¶
Compute model score instability from the base split to all comparison splits that are set in the current context. By default, instability is measured using Wasserstein Distance.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
score_type |
Optional[str] |
The score type to use when computing instability. If None, defaults to score type of project. Defaults to None. For a list of valid score types, see |
None |
use_difference_of_means |
bool |
If True, measures instability with Difference of Means. Defaults to False. |
False |
plot |
bool |
If True, plots performances for all base and comparison splits in the current context. |
False |
Returns:
| Type | Description |
|---|---|
Union[float, pd.DataFrame] |
The model score instability. If comparison data splits are set, a pd.DataFrame of all splits and their respective score instabilities. Otherwise, a single float metric is returned. |
Examples:
# Assuming `tru` is a `TrueraWorkspace`.
# Setup the project
>>> project_name = 'test_explainer'
>>> tru.add_project(project_name, score_type='regression', input_type='tabular')
>>> tru.add_data_collection('dc')
# Create train data. y = 2*x + 1 over range 'x <= 49.0 AND x >= -50.0'
>>> xs_train = pd.DataFrame({
"x": range(-50, 50)
})
>>> ys_train = 2 * xs_train["x"] + 1
# Create test data. Add (seeded) random noise to segment 'x <= 49.0 AND x >= 0.0'.
>>> rng = np.random.default_rng(seed=42)
>>> noise = rng.random(50)
>>> xs_test = xs_train.copy()
>>> ys_test = ys_train.copy() + np.concatenate([np.zeros(50), noise])
# Create another split that will produce high instability. y = -2*x + 1
>>> xs_invert = xs_train.copy()
>>> ys_invert = -2 * xs_train["x"] + 1
# Add data splits to project
>>> tru.add_data_split('train', pre_data = xs_train, label_data = ys_train, split_type = "train")
>>> tru.add_data_split('test', pre_data = xs_test, label_data = ys_test, split_type = "test")
>>> tru.add_data_split('invert', pre_data = xs_invert, label_data = ys_invert, split_type = "validate")
# create xgb model
>>> import xgboost as xgb
>>> params = {"model_type": "xgb.XGBRegressor", "eta": 0.2, "max_depth": 4}
>>> xgb_reg = xgb.XGBRegressor(eta = params['eta'], max_depth = params['max_depth'])
>>> xgb_reg.fit(xs_train, ys_train)
# add model to project
>>> tru.add_python_model("xgb", xgb_reg, train_split_name="train", train_parameters=params)
# Create an explainer and set the comparison splits
>>> explainer = tru.get_explainer("train")
>>> explainer.set_comparison_data_splits(["test", "invert"])
# Denote the score_type and call the method
>>> score_type = "mean_absolute_error_for_regression"
>>> explainer.compute_model_score_instability(score_type=score_type)
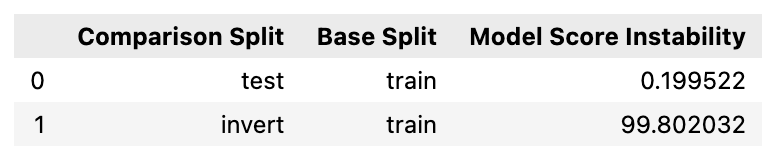
compute_partial_dependencies(self, wait=True)
¶
Get the partial dependencies for all features. Partial dependencies capture the marginal effect of a feature's value on the predicted outcome of the model.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
wait |
bool |
Whether to wait for the job to finish. Defaults to True. |
True |
Returns:
| Type | Description |
|---|---|
Tuple[Sequence[str], Mapping[str, Sequence], Mapping[str, Sequence]] |
The partial dependencies described in a 3-tuple: A list of the features, a mapping from feature to the x-values in a PDP, and a mapping from feature to the y-values in a PDP. |
Examples:
# Assuming `tru` is a `TrueraWorkspace`.
# Setup the project
>>> import numpy as np
>>> import pandas as pd
>>> project_name = 'test_explainer_pdp'
>>> tru.add_project(project_name, score_type='regression', input_type='tabular')
>>> tru.add_data_collection('dc')
# Create train data. y = 2*x + 1 over range 'x <= 49.0 AND x >= -50.0'
>>> xs_train = pd.DataFrame({
"x": range(-50, 50),
"cat": [0]*50 + [1]*50
})
# For ys, inject noise when x >= 0
>>> noise_gain = 5
>>> rng = np.random.default_rng(seed=42)
>>> noise = noise_gain*rng.random(50)
>>> ys_train = 2 * xs_train["x"] + 1
>>> ys_train = ys_train + np.concatenate([np.zeros(50), noise])
# Create data splits.
>>> tru.add_data_split('train', pre_data = xs_train, label_data = ys_train, split_type = "train")
# create xgb model
>>> import xgboost as xgb
>>> params = {"model_type": "xgb.XGBRegressor", "eta": 0.2, "max_depth": 4}
>>> xgb_reg = xgb.XGBRegressor(eta = params['eta'], max_depth = params['max_depth'])
>>> xgb_reg.fit(xs_train, ys_train)
# add model to project
>>> tru.add_python_model("xgb", xgb_reg, train_split_name="train", train_parameters=params)
# create explainer, compute partial dependencies (PDs)
>>> explainer = tru.get_explainer("train")
>>> pds = explainer.compute_partial_dependencies()
>>> features, xs, ys = pds
# Plot the PDs manually, accounting for numerical vs. categorical features
>>> import matplotlib.pyplot as plt
>>> for i, feature in enumerate(features):
>>> plt.figure()
>>> if i == 0: # numerical feature (x)
>>> plt.plot(xs[feature], ys[feature])
>>> if i == 1: # categorical feature (cat)
>>> plt.bar(xs[feature], ys[feature])
>>> plt.title(feature)
compute_performance(self, metric_type, plot=False)
¶
Compute performance metric.
Examples:
# Assuming `tru` is a `TrueraWorkspace`.
tru.set_model("model1")
explainer = tru.get_explainer("split1")
# This will compute AUC metrics for "split1".
explainer.compute_performance("AUC")
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
metric_type |
str |
Name of performance metric. Must be one of the options returned by |
required |
plot |
bool |
If True, plots performances for all base and comparison splits in the current context. |
False |
Returns:
| Type | Description |
|---|---|
Union[float, pd.DataFrame] |
The performance metric. If comparison data splits are set, a pd.DataFrame of all splits and their respective performance. Otherwise, a single float metric is returned. |
find_hotspots(self, num_features=1, max_num_responses=3, num_samples=100, metric_of_interest=None, metrics_to_show=None, minimum_size=50, minimum_metric_of_interest_threshold=0, size_exponent=0.25, comparison_data_split_name=None, bootstrapping_fraction=1, random_state=0, show_what_if_performance=False, use_labels=True)
¶
Suggests high error segments for the model for the currently set data split.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
num_features |
int |
Number of features to use to describe a high error segment. Defaults to 1. |
1 |
max_num_responses |
int |
Maximum number of high error segments to return. Defaults to 3. |
3 |
num_samples |
int |
Number of samples to use while attempting to find high error segments. The higher the number of samples the slower the computation, but the better the high error segments are generally. Defaults to 100. |
100 |
metric_of_interest |
Optional[str] |
Name specifying how segments are chosen. When None, defaults internally to either 'SEGMENT_GENERALIZED_AUC' or 'MAE' for classification or regression, respectively. Defaults to None. |
None |
metrics_to_show |
Optional[Union[str, Sequence[str]]] |
Name of performance metric or list of them to include. Must be one of the options returned by |
None |
minimum_size |
int |
Minimum size of a segment. Defaults to 50. |
50 |
minimum_metric_of_interest_threshold |
float |
Minimum difference between segment and comparison (i.e. entire split when |
0 |
size_exponent |
float |
Exponential factor on size of segment. Should be in [0, 1]. A zero value implies the segment size has no effect. Defaults to 0.25. |
0.25 |
comparison_data_split_name |
Optional[str] |
Comparison data-split to use (e.g. train split for overfitting analysis). If set, we look for segments that are far more problematic in the explainer's data split than the comparison one supplied here. |
None |
bootstrapping_fraction |
float |
Random fraction of points to use for analysis. Should be in (0, 1]. Defaults to 1. |
1 |
random_state |
int |
Random seed for two random processes: 1) selecting the features to analyze and 2) choosing points in bootstrapping. If |
0 |
show_what_if_performance |
bool |
Whether to show the "what if" performance of the segment, defined as what the overall accuracy on the split would be if the segment's performance were brought up to the accuracy on the whole split. The "what if" version of a metric can only be defined if the metric can be defined per-point and averaged over. Defaults to False. |
False |
use_labels |
bool |
Whether to use the labels as a feature for segmentation. Defaults to True. |
True |
Returns:
| Type | Description |
|---|---|
pd.DataFrame |
DataFrame describing high error segments. Each row corresponds to a suggested high error segment, with the following columns: 1. segment_definition: The segment definition which can be ingested via the workspace add_segment_group function. 2. size: The number of points in this segment in total in the base data split. In the presence of a comparison split, this will also include ({base_data_split_name}). 3. size (%): The percentage of points in this segment in the base data split. In the presence of a comparison split, this will also include ({base_data_split_name}). There will also be additional columns corresponding to: A. The metric of interest along with a column for each metric in metrics_to_show. B. The "what if" metric corresponding to the metric of interest (if viable) along with each viable "what if" metric in metrics_to_show. Only displayed when show_what_if_performance is True. C. size ({comparison_data_split_name}) and size (%) ({comparison_data_split_name}): The same size and size (%) as above but for the comparison data split. Only displayed when comparison_data_split_name is provided. D. size diff (%): The absolute difference in size (%) between base and comparison data split. Only displayed when metric_of_interest is UNDER_OR_OVERSAMPLING. |
Examples:
# Assuming `tru` is a `TrueraWorkspace`.
# Setup the project
>>> project_name = 'test_explainer'
>>> tru.add_project(project_name, score_type='regression', input_type='tabular')
>>> tru.add_data_collection('dc')
# Create train data. y = 2*x + 1 over range 'x <= 49.0 AND x >= -50.0'
>>> xs_train = pd.DataFrame({
"x": range(-50, 50)
})
>>> ys_train = 2 * xs_train["x"] + 1
# Create test data. Add (seeded) random noise to segment 'x <= 49.0 AND x >= 0.0'.
>>> rng = np.random.default_rng(seed=42)
>>> noise = rng.random(50)
>>> xs_test = xs_train.copy()
>>> ys_test = ys_train.copy() + np.concatenate([np.zeros(50), noise])
# Create data splits.
>>> tru.add_data_split('train', pre_data = xs_train, label_data = ys_train, split_type = "train")
>>> tru.add_data_split('test', pre_data = xs_test, label_data = ys_test, split_type = "test")
# create xgb model
>>> import xgboost as xgb
>>> params = {"model_type": "xgb.XGBRegressor", "eta": 0.2, "max_depth": 4}
>>> xgb_reg = xgb.XGBRegressor(eta = params['eta'], max_depth = params['max_depth'])
>>> xgb_reg.fit(xs_train, ys_train)
# add model to project
>>> tru.add_python_model("xgb", xgb_reg, train_split_name="train", train_parameters=params)
# create explainer and return high_error_segments
>>> explainer = tru.get_explainer("test")
>>> explainer.find_hotspots(
metric_of_interest="MSE"
)

# return high_error_segments without labels as segment feature
>>> explainer.find_hotspots(
metric_of_interest="MSE",
use_labels=False
)

# return high_error_segments with multiple segment metrics
>>> explainer.find_hotspots(
metric_of_interest="MSE",
metrics_to_show=["MAE"],
use_labels=False
)

# return high_error_segments with comparison split
>>> explainer.find_hotspots(
metric_of_interest="MSE",
use_labels=False,
comparison_data_split_name="train"
)

get_base_data_split(self)
inherited
¶
Get the base data split used by explainer.
Returns:
| Type | Description |
|---|---|
str |
The name of the base data split. |
get_comparison_data_splits(self)
inherited
¶
Gets the comparison data splits used by the explainer.
Returns:
| Type | Description |
|---|---|
Sequence[str] |
The names of the comparison data splits. |
get_data_collection(self)
inherited
¶
Get the data collection name used by explainer.
get_feature_names(self)
inherited
¶
Get the feature names associated with the current data-collection.
Returns:
| Type | Description |
|---|---|
Sequence[str] |
Feature names. |
get_global_feature_importances(self, score_type=None, wait=True)
¶
Get the global feature importances (as measured by QIIs) for this explainer's currently set data split.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
score_type |
Optional[str] |
The score type to use when computing influences. If None, defaults to score type of project. Defaults to None. For a list of valid score types, see |
None |
wait |
bool |
Whether to wait for the job to finish. |
True |
Returns:
| Type | Description |
|---|---|
pd.DataFrame |
The normalized global importances for each feature. |
get_spline_fitter(self, start=0, stop=None)
inherited
¶
Get the spline-fitter using the provided range of points to fit splines.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
start |
int |
The lower bound (inclusive) of the index of points to use during spline fitting. Defaults to 0. |
0 |
stop |
Optional[int] |
The upper bound (exclusive) of the index of points to use during spline fitting. Defaults to the number of Number of default influences for the project. |
None |
Returns:
| Type | Description |
|---|---|
SplineFitter |
Spline-fitter. |
Examples:
# Assuming `tru` is a `TrueraWorkspace`.
tru.set_model("model1")
explainer = tru.get_explainer("split1")
# Construct a spline fitter and use it to construct a GAM.
sf = explainer.get_spline_fitter("segment_group1", "segment1_in_segment_group1")
gam = sf.construct_gam(
n_splines=10,
spline_orders=3,
constraints={"feature2": "monotonic_inc", "feature5": "monotonic_dec"}
)
# Add GAM model into TruEra.
tru.add_python_model("GAM from model1", gam)
get_xs(self, start=0, stop=None, extra_data=False, system_data=False, by_group=False, num_per_group=None)
inherited
¶
Get the inputs/data/x-values.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
start |
Optional[int] |
The lower bound (inclusive) of the index of points to include. Defaults to 0. |
0 |
stop |
Optional[int] |
The upper bound (exclusive) of the index of points to include. Defaults to None which is interpreted as the total number of points for local projects and the setting for "Number of default influences" for remote projects. |
None |
extra_data |
bool |
Include extra data columns in the response. |
False |
system_data |
bool |
Include system data columns (unique ID) in the response. |
False |
by_group |
bool |
For ranking projects, whether to retrieve data by group or not. Ignored for non-ranking projects. Defaults to False. |
False |
num_per_group |
Optional[int] |
For ranking projects and when |
None |
Returns:
| Type | Description |
|---|---|
pd.DataFrame |
The inputs/data/x-values. |
get_ys(self, start=0, stop=None, system_data=False, by_group=False, num_per_group=None)
inherited
¶
Get the targets/y-values.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
start |
Optional[int] |
The lower bound (inclusive) of the index of points to include. Defaults to 0. |
0 |
stop |
Optional[int] |
The upper bound (exclusive) of the index of points to include. Defaults to None which is interpreted as the total number of points for local projects and the setting for "Number of default influences" for remote projects. |
None |
system_data |
bool |
Include system data columns (unique ID) in the response. |
False |
by_group |
bool |
For ranking projects, whether to retrieve data by group or not. Ignored for non-ranking projects. Defaults to False. |
False |
num_per_group |
Optional[int] |
For ranking projects and when |
None |
Returns:
| Type | Description |
|---|---|
pd.DataFrame |
The targets/y-values as a pd.DataFrame. |
get_ys_pred(self, start=0, stop=None, system_data=False, by_group=False, num_per_group=None, wait=True)
inherited
¶
Get the model predictions.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
start |
Optional[int] |
The lower bound (inclusive) of the index of points to include. Defaults to 0. |
0 |
stop |
Optional[int] |
The upper bound (exclusive) of the index of points to include. Defaults to None which is interpreted as the total number of points for local projects and the setting for "Number of default influences" for remote projects. |
None |
system_data |
bool |
Include system data (e.g. timestamps) if available in response. Defaults to False. |
False |
by_group |
bool |
For ranking projects, whether to retrieve data by group or not. Ignored for non-ranking projects. Defaults to False. |
False |
num_per_group |
Optional[int] |
For ranking projects and when |
None |
wait |
bool |
Whether to wait for the job to finish. Defaults to True. |
True |
Returns:
| Type | Description |
|---|---|
pd.DataFrame |
The model predictions as a pd.DataFrame. |
Examples:
# Assuming `tru` is a `TrueraWorkspace`.
>>> tru.set_model("model1")
>>> explainer = tru.get_explainer("split1")
# This will return "model1"'s predictions on "split1".
>>> explainer.get_ys_pred()
list_performance_metrics(self)
¶
Lists all available performance metrics.
Returns:
| Type | Description |
|---|---|
Sequence[str] |
List of performance metric names, which can be provided to |
plot_isp(self, feature, num=None, figsize=(700, 500), xlim=None)
¶
Plot the influence sensitivity plot (ISP) of a specific feature.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
feature |
str |
Feature to plot the ISP of. |
required |
num |
Optional[int] |
Number of points to plot. Defaults to None, which is equivalent to a standard number of points used for calculations. |
None |
figsize |
Optional[Tuple[int, int]] |
Size for plot in pixels. Defaults to (700, 500). |
(700, 500) |
xlim |
Optional[Tuple[int, int]] |
Range for x-axis. Defaults to None, which scales to the size of the data. |
None |
plot_isps(self, features=None, num=None, figsize=(700, 500))
¶
Plot the influence sensitivity plot (ISP) of a set of features.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
features |
Optional[Sequence[str]] |
Features to plot the ISP of. Defaults to None, which is all features. |
None |
num |
Optional[int] |
Number of points to plot. Defaults to None, which is equivalent to a standard number of points used for calculations. |
None |
figsize |
Optional[Tuple[int, int]] |
Size for plot. Defaults to (21, 6). |
(700, 500) |
plot_pdp(self, feature, figsize=(700, 500), xlim=None)
¶
DEPRECATED: Plot the partial dependence plot (PDP) of a specific feature.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
feature |
str |
Feature to plot the PDP of. |
required |
figsize |
Optional[Tuple[int, int]] |
Size for plot. Defaults to (21, 6). |
(700, 500) |
xlim |
Optional[Tuple[int, int]] |
Range for x-axis. Defaults to None, which scales to the size of the data. |
None |
plot_pdps(self, features=None, figsize=(700, 500))
¶
DEPRECATED: Plot the partial dependence plot (PDP) of a set of features.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
features |
Optional[Sequence[str]] |
Features to plot the PDP of. Defaults to None, which is all features. |
None |
figsize |
Optional[Tuple[int, int]] |
Size for plot. Defaults to (21, 6). |
(700, 500) |
rank_performance(self, metric_type, ascending=False)
¶
Rank performance of all models in the data collection on the explainer's base data split. If comparison data splits are set, will also show performance of the models on them.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
metric_type |
str |
Name of performance metric. Must be one of the options returned by |
required |
ascending |
bool |
If True, sort the results in ascending order. Defaults to False. |
False |
Returns:
| Type | Description |
|---|---|
pd.DataFrame |
The performance score of all models in the data collection. |
set_base_data_split(self, data_split_name=None)
inherited
¶
Set the base data split to use for all operations in the explainer.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
data_split_name |
Optional[str] |
Name of the data split. |
None |
Examples:
# Assuming `tru` is a `TrueraWorkspace`.
>>> explainer = tru.get_explainer("split1")
# Gets labels for data-split "split1".
>>> explainer.get_ys()
>>> explainer.set_base_data_split("split2")
# Gets labels for data-split "split2".
>>> explainer.get_ys()
set_comparison_data_splits(self, comparison_data_splits=None, use_all_data_splits=False)
inherited
¶
Sets comparison data splits to use for all operations in the explainer.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
comparison_data_splits |
Optional[Sequence[str]] |
List of data split names for comparison. This is ignored if |
None |
use_all_data_splits |
bool |
If set to True, set comparison data splits as all of the data splits in the data collection except the base data split. (Optional) |
False |
Examples:
# Assuming `tru` is a `TrueraWorkspace`.
>>> explainer = tru.get_explainer("split1")
>>> explainer = tru.set_comparison_data_splits(["split2", "split3"])
# This will compute AUC metrics for "split1" and compare to "split2" and "split3".
>>> explainer.compute_performance("AUC")
set_segment(self, segment_group_name, segment_name)
inherited
¶
Sets and applies a segment filter to all explainer operations.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
segment_group_name |
str |
Name of segment group under which the segment is defined. |
required |
segment_name |
str |
Name of the segment. |
required |
Examples:
# Assuming `tru` is a `TrueraWorkspace`.
>>> explainer = tru.get_explainer("split1")
# This will return all the xs in "split1".
>>> explainer.get_xs()
>>> explainer.set_segment("segment_group1", "segment1_in_segment_group1")
# This will return only the xs in "split1" filtered to the segment "segment1_in_segment_group1".
>>> explainer.get_xs()
IngestionClient
¶
Client for ingesting data from a variety of sources into the TruEra product.
add_credential(self, name, secret, identity=None, is_aws_iam_role=False)
¶
Add a new credential to TruEra product. The credential is saved in a secure manner and is used to authenticate with the data source to be able to perform various operations (read, filter, sample etc.).
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
name |
str |
Friendly name of the credential. |
required |
secret |
str |
The secret to be stored. |
required |
identity |
str |
Identity portion of the secret. Not needed in all cases. Defaults to None. |
None |
Returns:
| Type | Description |
|---|---|
Credential |
Returns an object with the credential name and id. The secret is not stored in this object. |
Examples:
>>> ACCESS_KEY = "access_key"
>>> SECRET_KEY = "asdf1234asdf1234"
>>> ingestion_client.add_credential(
name="credential_1",
secret=SECRET_KEY,
identity=ACCESS_KEY
)
add_data_source(self, name, uri, credentials=None, **kwargs)
¶
Add a new data source in the system.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
name |
str |
Friendly name of the data source. |
required |
uri |
str |
URI describing the location of the data source.
For local files this can be file:///path/to/my/file or /path/to/my/file
For files stored in Azure Storage Blobs the expected path is wasb://container@account.blob.core.windows.net/blob
For files stored in S3 Buckets the expected path is s3://bucket-name/file
For mysql connections the expected path is mysql://database-endpoint.com:port
For hive connections the expected path is hive2://database-endpoint.com:port
For jdbc connections the expected path is jdbc: |
required |
credentials |
Credential |
Provide the credential object if the data source requires authentication to read from it. Defaults to None. |
None |
**format |
str |
The format in which the file (local) or blob (AWS S3, Azure WASB etc.) are stored in. Supported formats: CSV and Parquet. |
required |
**column_schema |
Union[str, List[Tuple[str, str]]] |
For providing a schema that should be respected by the data source. This can be provided in the form of a path to a JSON/YAML file containing the schema, or a list columns each represented as a tuple |
required |
**first_row_is_header |
bool |
For text based delimited files (csv, tsv etc.), indicates if the first row provides header information. Defaults to True. |
required |
**column_delimiter |
str |
For text based delimited files (csv, tsv etc.), provides the delimiter to separate column values. Defaults to ','. |
required |
**quote_character |
str |
For text based delimited files (csv, tsv etc.), if quotes are used provide the quote character. Defaults to '"'. |
required |
**null_value |
str |
For text based delimited files (csv, tsv etc.), the string that signifies null value. Defaults to 'null'. |
required |
**empty_value |
str |
For text based delimited files (csv, tsv etc.), the string that signifies empty value. Defaults to '""'. |
required |
**date_format |
str |
For text based delimited files (csv, tsv etc.), if any column has date time, provide the format string. Defaults to 'yyyy-MM-dd HH |
required |
**account_key |
str |
For reading from Azure Storage Blob (WASB), provide the account_key to be used to read the blob. Not required if |
required |
**access_key_id |
str |
For reading from a s3 bucket, provide the access key id to be used to read the blob. Not required if |
required |
**secret_access_key |
str |
For reading from a s3 bucket, provide the secret access key to be used to read the blob. Not required if |
required |
**database_name |
str |
For reading from MySQL database, provide the database name to use. Required for MySQL data source. |
required |
**table_name |
str |
For reading from MySQL database, provide the table name to use. Required for MySQL data source. |
required |
Returns:
| Type | Description |
|---|---|
Table |
Returns a Table object which allows interaction with the attached data. |
Examples:
# Adding a local file
>>> table = ingestion_client.add_data_source(
name="local_data_1",
uri="path/to/data.parquet"
)
# Adding a data source from S3
>>> credentials = ingestion_client.add_credential(
name="s3_credential", secret="...", identity="..."
)
>>> table = ingestion_client.add_data_source(
name="s3_data_1",
uri="s3://some-data-bucket/data.parquet",
credentials=credentials
)
delete_credential(self, name)
¶
Delete a credential in the TruEra product.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
name |
str |
Friendly name of the credential. |
required |
Examples:
>>> ingestion_client.delete_credential("credential_1")
get_credential(self, name)
¶
Get metadata about a credential in the TruEra product. Response does not contain the credential itself.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
name |
str |
Friendly name of the credential. |
required |
Returns:
| Type | Description |
|---|---|
dict |
Dictionary containing metadata describing that credential. |
Examples:
>>> credential_metadata = ingestion_client.get_credential("credential_1")
get_data_source(self, name)
¶
Get a data source that was already created in the system.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
name |
str |
The friendly name of the data source. |
required |
Returns:
| Type | Description |
|---|---|
Table |
Returns a Table object which allows interaction with the attached data. |
Examples:
>>> table = ingestion_client.get_data_source("table1")
update_credential(self, name, secret, identity=None)
¶
Update the identity and/or secret of an existing credential.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
name |
str |
Friendly name of the credential. |
required |
secret |
str |
The secret to be stored. |
required |
identity |
str |
Identity portion of the secret. Not needed in all cases. Defaults to None. |
None |
Returns:
| Type | Description |
|---|---|
Credential |
Returns an object with the credential name and id. The secret is not stored in this object. |
Examples:
>>> ACCESS_KEY = "access_key"
>>> SECRET_KEY = "asdf1234asdf1234"
>>> ingestion_client.add_credential(
name="credential_1",
secret=SECRET_KEY,
identity=ACCESS_KEY
)
>>> ingestion_client.update_credentials(
name="credential_1",
secret="new_secret_1234",
identity="new_identity"
)
Table
¶
add_data_split(self, data_split_name, data_split_type, label_col_name=None, id_col_name=None, sample_count=5000, sample_kind='random', *, seed=None, prediction_col_name=None, pre_data_additional_skip_cols=None, model_name=None, wait=True, timeout_seconds=300, timestamp_col_name=None, score_type=None, train_baseline_model=False, **kwargs)
¶
Ingest the Table as a split in TruEra to use in analytics.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
data_split_name |
str |
Name of the data split. |
required |
data_split_type |
str |
Type of the data split, options are ['all', 'train', 'test', 'validate', 'oot', 'custom'] |
required |
label_col_name |
str |
Name of the label/ground truth/target column in the table. |
None |
sample_count |
int |
Maximum rows to use when creating the split. Defaults to 5000. |
5000 |
sample_kind |
str |
Specifies the strategy to use while sub-sampling the rows. Defaults to "random". |
'random' |
wait |
bool |
Whether to wait for the TruEra service to complete creating the data split. Defaults to True. |
True |
timeout_seconds |
int |
Timeout used when |
300 |
Returns:
| Type | Description |
|---|---|
Mapping[str, str] |
Returns a dictionary with |
add_extra_data(self, data_split_name, extras_col_names, id_col_name, sample_count=5000, sample_kind='random', *, timestamp_col_name=None, seed=None, wait=True, timeout_seconds=300, **kwargs)
¶
Upload extra_data from Table to an existing split in TruEra.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
data_split_name |
str |
Name of the existing data split. |
required |
extras_col_names |
Union[str, Sequence[str]] |
Name(s) of the extra data column(s) in the table. |
required |
id_col_name |
str |
Name of the id column used to match extra data with the corresponding data points. |
required |
sample_count |
int |
Maximum rows to use when creating the split. Defaults to 5000. |
5000 |
sample_kind |
str |
Specifies the strategy to use while sub-sampling the rows. One of ["random", "first"]. |
'random' |
timestamp_col_name |
Optional[str] |
Name of the timestamp column of the extra data. |
None |
wait |
bool |
Whether to wait for the TruEra service to complete creating the data split. Defaults to True. |
True |
timeout_seconds |
int |
Timeout used when |
300 |
Returns:
| Type | Description |
|---|---|
Mapping[str, str] |
Returns a dictionary with |
add_feature_influences(self, data_split_name, feature_influence_col_names, id_col_name, model_name, *, background_split_name=None, timestamp_col_name=None, score_type=None, wait=True, timeout_seconds=300, influence_type=None, **kwargs)
¶
Upload feature influences from Table to an existing split/model in TruEra.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
data_split_name |
str |
Name of the existing data split. |
required |
feature_influence_col_names |
Sequence[str] |
Name of the feature influence columns in the table. |
required |
id_col_name |
str |
Name of the id column used to match predictions with the corresponding data points. |
required |
model_name |
str |
Name of the model for which feature influences are computed. |
required |
background_split_name |
Optional[str] |
Split name that contains the background of feature influence computation. If not provided, defaults to the default background data split of the given data collection. |
None |
timestamp_col_name |
Optional[str] |
Name of the timestamp column of the predictions. |
None |
score_type |
Optional[str] |
String name of score type (QoI) for prediction column. |
None |
wait |
bool |
Whether to wait for the TruEra service to complete creating the data split. Defaults to True. |
True |
timeout_seconds |
int |
Timeout used when |
300 |
influence_type |
Optional[str] |
Influence algorithm used to generate influences.
If influence type of project is set to "truera-qii", assumes that explanations are generated using truera-qii.
If influence type of project is set to "shap", then |
None |
Returns:
| Type | Description |
|---|---|
Mapping[str, str] |
Returns a dictionary with |
add_labels(self, data_split_name, label_col_name, id_col_name, sample_count=5000, sample_kind='random', *, timestamp_col_name=None, seed=None, wait=True, timeout_seconds=300, model_name=None, **kwargs)
¶
Upload labels from Table to an existing split in TruEra.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
data_split_name |
str |
Name of the existing data split. |
required |
label_col_name |
str |
Name of the label/ground truth/target column in the table. |
required |
id_col_name |
str |
Name of the id column used to match labels with the corresponding data points. |
required |
sample_count |
int |
Maximum rows to use when creating the split. Defaults to 5000. |
5000 |
sample_kind |
str |
Specifies the strategy to use while sub-sampling the rows. One of ["random", "first"]. |
'random' |
timestamp_col_name |
Optional[str] |
Name of the timestamp column of the labels. |
None |
wait |
bool |
Whether to wait for the TruEra service to complete creating the data split. Defaults to True. |
True |
timeout_seconds |
int |
Timeout used when |
300 |
Returns:
| Type | Description |
|---|---|
Mapping[str, str] |
Returns a dictionary with |
add_predictions(self, data_split_name, prediction_col_name, id_col_name, model_name, *, timestamp_col_name=None, score_type=None, wait=True, timeout_seconds=300, **kwargs)
¶
Upload predictions from Table to an existing split/model in TruEra.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
data_split_name |
str |
Name of the existing data split. |
required |
prediction_col_name |
str |
Name of the prediction column in the table. |
required |
id_col_name |
str |
Name of the id column used to match predictions with the corresponding data points. |
required |
timestamp_col_name |
Optional[str] |
Name of the timestamp column of the predictions. |
None |
score_type |
Optional[str] |
String name of score type (QoI) for prediction column. |
None |
wait |
bool |
Whether to wait for the TruEra service to complete creating the data split. Defaults to True. |
True |
timeout_seconds |
int |
Timeout used when |
300 |
Returns:
| Type | Description |
|---|---|
Mapping[str, str] |
Returns a dictionary with |
append_to_data_split(self, data_split_name, id_col_name, *, sample_count=5000, sample_kind='random', seed=None, label_col_name=None, prediction_col_name=None, wait=True, timeout_seconds=300, timestamp_col_name=None, model_name=None, score_type=None, **kwargs)
¶
Ingest the Table into an existing split in TruEra to use in analytics. All columns of the data frame will be ingested into pre_data except for label / prediction columns if specified.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
data_split_name |
str |
Name of the data split. |
required |
id_col_name |
str |
Name of the column to use for unique ID. |
required |
sample_count |
int |
Maximum rows to use when creating the split. Defaults to 5000. |
5000 |
sample_kind |
str |
Specifies the strategy to use while sub-sampling the rows. Options are "random" and "first". It is not recommended to use "first" as it may result in a non-uniform sampling. Defaults to "random". |
'random' |
label_col_name |
str |
Name of the label/ground truth/target column in the table. |
None |
prediction_col_name |
str |
Name of the prediction column in the table. |
None |
timestamp_col_name |
str |
Name of the timestamp column (if using). |
None |
seed |
int |
Seed for reproducing the same ingestion - defaults to a random seed. |
None |
wait |
bool |
Whether to wait for the TruEra service to complete creating the data split. Defaults to True. |
True |
timeout_seconds |
int |
Timeout used when |
300 |
Returns:
| Type | Description |
|---|---|
Mapping[str, str] |
Returns a dictionary with |
filter(self, expression)
¶
[Alpha] Filter a table by providing a boolean expression.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
expression |
str |
The expression to filter the table. Simple SQL expressions are supported:
|
required |
Exceptions:
| Type | Description |
|---|---|
ValueError |
Raised if provided expression is |
Returns:
| Type | Description |
|---|---|
Table |
Returns a table which points to the filtered rows. |
get_sample_rows(self, count=10, *, wait=True, timeout_seconds=300)
¶
Get sampled rows from the table.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
count |
int |
The number of rows to sample. Maximum allowed is 2000. Defaults to 100. |
10 |
wait |
bool |
If set to true, the client will wait until timeout to get data from the service. This is useful when the data is still being fetched or filtered. Defaults to True. |
True |
timeout_seconds |
int |
Timeout used when |
300 |
Returns:
| Type | Description |
|---|---|
pd.DataFrame |
Returns a pandas DataFrame containing the sampled rows. |
merge_dataframes_and_create_column_spec(id_col_name, timestamp_col_name=None, pre_data=None, post_data=None, predictions=None, labels=None, extra_data=None, feature_influences=None, feature_influence_suffix='_truera-qii_influence')
¶
Helper function to merge multiple DataFrames into one and generate a ColumnSpec
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
id_col_name |
str |
Id column name. |
required |
timestamp_col_name |
Optional[str] |
Timestamp column name. Defaults to None. |
None |
pre_data |
Optional[pd.DataFrame] |
DataFrame corresponding to pre data. Defaults to None. |
None |
post_data |
Optional[pd.DataFrame] |
DataFrame corresponding to post data. Defaults to None. |
None |
predictions |
Optional[pd.DataFrame] |
DataFrame corresponding to predictions. Defaults to None. |
None |
labels |
Optional[pd.DataFrame] |
DataFrame corresponding to labels. Defaults to None. |
None |
extra_data |
Optional[pd.DataFrame] |
DataFrame corresponding to extra data. Defaults to None. |
None |
feature_influences |
Optional[pd.DataFrame] |
DataFrame correspondnig to feature influences. Defaults to None. |
None |
feature_influence_suffix |
Optional[str ] |
Suffix to append to column names of feature influences in order to prevent duplicate name issues. Defaults to FEATURE_INFLUENCE_SUFFIX_TRUERA_QII. |
'_truera-qii_influence' |
Returns:
| Type | Description |
|---|---|
Tuple[pd.DataFrame, ColumnSpec] |
A tuple consisting of the merged DataFrame and corresponding ColumnSpec |
Segment
¶
apply(self, data)
¶
Applies the filter associated with this segment to the provided data.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
data |
DataFrame |
Data to apply segment on. |
required |
Returns:
| Type | Description |
|---|---|
np.ndarray |
Boolean array of same length of |
pretty_print(self)
¶
Print out the filter associated with this segment.
SplineFitter
¶
__init__(self, xs, ys, qiis)
special
¶
Construct a spline fitter.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
xs |
pd.DataFrame |
x-values. |
required |
ys |
Union[pd.DataFrame, np.ndarray] |
y-values. |
required |
qiis |
pd.DataFrame |
QII/influences/shapley-values. |
required |
construct_gam(self, n_splines=10, spline_orders=3, constraints=None, outer_model=LogisticRegression())
¶
Construct a GAM based off QII splines.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
n_splines |
int |
Number of splines per feature. Defaults to 10. |
10 |
spline_orders |
int |
Order of splines. Defaults to 3. |
3 |
constraints |
Union[str, Mapping[str, str]] |
If a single str, then the constraints for all features. Otherwise a dict from feature to constraints. All constraints must be one of [None, "monotonic_inc", "monotonic_dec"]. Defaults to None. |
None |
outer_model |
Any |
Model to combine splines. This must work with sklearn.pipeline.Pipeline. Defaults to LogisticRegression(). |
LogisticRegression() |
Returns:
| Type | Description |
|---|---|
Pipeline |
GAM model. |
fit_spline(self, feature, n_splines=10, spline_order=1, constraints=None)
¶
Compute a spline for a single feature.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
feature |
str |
Feature to compute splines for. |
required |
n_splines |
int |
Number of splines per feature. Defaults to 10. |
10 |
spline_order |
int |
Order of splines. Defaults to 3. |
1 |
constraints |
str |
The constraints for the spline --- must be one of [None, "monotonic_inc", "monotonic_dec"]. Defaults to None. |
None |
Returns:
| Type | Description |
|---|---|
Callable[[Union[pd.Series, np.ndarray]], np.ndarray] |
Spline. |
plot_isp(self, feature, figsize=(21, 6))
¶
Plot the influence sensitivity plot (ISP) of a specific feature along with the associated spline.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
feature |
str |
Feature to plot the ISP of. |
required |
figsize |
Tuple[int, int] |
Size for plot. Defaults to (21, 6). |
(21, 6) |
plot_isps(self, features=None, figsize=(21, 6))
¶
Plot the influence sensitivity plot (ISP) of a set of features along with the associated spline.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
features |
Sequence[str] |
Features to plot the ISP of. Defaults to None, which is all features. |
None |
figsize |
Tuple[int, int] |
Size for plot. Defaults to (21, 6). |
(21, 6) |
Tester
¶
add_fairness_test(self, test_name, metric='DISPARATE_IMPACT_RATIO', *, data_split_names=None, data_split_name_regex=None, all_protected_segments=False, protected_segments=None, comparison_segments=None, all_data_collections=False, data_collection_names=None, warn_if_less_than=None, warn_if_greater_than=None, warn_if_within=None, warn_if_outside=None, fail_if_less_than=None, fail_if_greater_than=None, fail_if_within=None, fail_if_outside=None, description=None, overwrite=False)
¶
Add a fairness test to the current data collection in context. To set warning condition, please provide one of [warn_if_less_than, warn_if_greater_than, warn_if_within, warn_if_outside].
Similarly, to set fail condition please provide one of [fail_if_less_than, fail_if_greater_than, fail_if_within, fail_if_outside].
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
test_name |
str |
The name of the test. |
required |
metric |
str |
Fairness metric for the test. Must be one of the options returned by |
'DISPARATE_IMPACT_RATIO' |
data_split_names |
Optional[Sequence[str]] |
List of the data splits that we want to use for the test. |
None |
all_protected_segments |
bool |
If set to |
False |
protected_segments |
Optional[Sequence[Tuple[str, str]]] |
List of |
None |
comparison_segments |
Optional[Sequence[Tuple[str, str]]] |
List of |
None |
data_collection_names |
Optional[Sequence[str]] |
List of the data collections for the test. If not specified, the test will only apply to the current data collection in context. |
None |
all_data_collections |
bool |
If set to |
False |
warn_if_less_than |
Optional[float] |
Warn if score is less than the value specified in this argument. |
None |
warn_if_greater_than |
Optional[float] |
Warn if score is greater than the value specified in this argument. |
None |
warn_if_within |
Optional[Tuple[float, float]] |
Warn if |
None |
warn_if_outside |
Optional[Tuple[float, float]] |
Warn if |
None |
fail_if_less_than |
Optional[float] |
Fail if score is less than the value specified in this argument. |
None |
fail_if_greater_than |
Optional[float] |
Fail if score is greater than the value specified in this argument. |
None |
fail_if_within |
Optional[Tuple[float, float]] |
Fail if |
None |
fail_if_outside |
Optional[Tuple[float, float]] |
Fail if |
None |
description |
Optional[str] |
Text description of the test. |
None |
overwrite |
bool |
If set to |
False |
Examples:
# Explicitly specifying comparison segment
>>> tru.tester.add_fairness_test(
test_name="Fairness Test",
data_split_names=["split1_name", "split2_name"],
protected_segments=[("segment_group_name", "protected_segment_name")],
comparison_segments=[("segment_group_name", "comparison_segment_name")],
comparison_segment_name=<comparison segment name>,
metric="DISPARATE_IMPACT_RATIO",
warn_if_outside=[0.8, 1.25],
fail_if_outside=[0.5, 2]
)
# Not specifying comparison segment means the comparison segment is the complement of protected segment
# will be used as comparison
>>> tru.tester.add_fairness_test(
test_name="Fairness Test",
data_split_names=["split1_name", "split2_name"],
protected_segments=[("segment_group_name", "protected_segment_name")],
metric="DISPARATE_IMPACT_RATIO",
warn_if_outside=[0.9, 1.15],
fail_if_outside=[0.8, 1.25]
)
add_feature_importance_test(self, test_name, *, data_split_names=None, data_split_name_regex=None, min_importance_value, background_split_name=None, score_type=None, segments=None, data_collection_names=None, warn_if_greater_than=None, fail_if_greater_than=None, description=None, overwrite=False)
¶
Add a feature importance test to the current data collection in context. To set warning condition, please provide warn_if_greater_than. Similarly, to set fail condition please provide fail_if_greater_than.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
test_name |
str |
The name of the test. |
required |
data_split_names |
Optional[Sequence[str]] |
List of the data splits that we want to use for the test. |
None |
data_split_name_regex |
Optional[str] |
Regex of the data split name that we want to use for the test (future data splits that match this naming pattern will automatically be included in the test). |
None |
min_importance_value |
float |
Minimum global importance value of a feature. |
required |
background_split_name |
Optional[str] |
The name of the data split to be used as background data for computing feature influences. If None, this value will be inferred from the project settings. Defaults to None. |
None |
score_type |
Optional[str] |
The score type to use when computing influences. If None, this value will be inferred from the project settings. Defaults to None. For a list of valid score types, see |
None |
segments |
Optional[Tuple[str, str]] |
List of |
None |
warn_if_greater_than |
Optional[float] |
Warn if more than this number of features have global importance values lower than |
None |
fail_if_greater_than |
Optional[float] |
Fail if more than this number of features have global importance values lower than |
None |
description |
Optional[str] |
Text description of the test. |
None |
overwrite |
bool |
If set to |
False |
Examples:
>>> tru.tester.add_feature_importance_test(
test_name="Feature Importance Test",
data_split_names=["split1_name", "split2_name"],
min_importance_value=0.01,
background_split_name="background split name",
score_type=<score_type>, # (e.g., "regression", or "logits"/"probits"
# for the classification project)
warn_if_greater_than=5, # warn if number of features with global importance values lower than `min_importance_value` is > 5
fail_if_greater_than=10
)
add_performance_test(self, test_name, metric, *, data_split_names=None, data_split_name_regex=None, all_data_collections=False, data_collection_names=None, segments=None, warn_if_less_than=None, warn_if_greater_than=None, warn_if_within=None, warn_if_outside=None, warn_threshold_type='ABSOLUTE', fail_if_less_than=None, fail_if_greater_than=None, fail_if_within=None, fail_if_outside=None, fail_threshold_type='ABSOLUTE', reference_split_name=None, reference_model_name=None, description=None, overwrite=False)
¶
Add a performance test group to the current data collection in context. To set warning condition, please provide one of [warn_if_less_than, warn_if_greater_than, warn_if_within, warn_if_outside].
Similarly, to set fail condition please provide one of [fail_if_less_than, fail_if_greater_than, fail_if_within, fail_if_outside].
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
test_name |
str |
The name of the test. |
required |
metric |
str |
Performance metric for the test. Must be one of the options returned by |
required |
data_split_names |
Optional[Sequence[str]] |
List of the data splits that we want to use for the test. |
None |
data_split_name_regex |
Optional[str] |
Regex of the data split name that we want to use for the test (future data splits that match this naming pattern will automatically be included in the test). |
None |
data_collection_names |
Optional[Sequence[str]] |
List of the data collections for the test. If not specified, the test will only apply to the current data collection in context. |
None |
all_data_collections |
bool |
If set to |
False |
segments |
Optional[Sequence[Tuple[str, str]]] |
List of |
None |
warn_if_less_than |
Optional[float] |
Warn if score is less than the value specified in this argument. |
None |
warn_if_greater_than |
Optional[float] |
Warn if score is greater than the value specified in this argument. |
None |
warn_if_within |
Optional[Tuple[float, float]] |
Warn if |
None |
warn_if_outside |
Optional[Tuple[float, float]] |
Warn if |
None |
warn_threshold_type |
str |
Must be one of ["ABSOLUTE", "RELATIVE"]. Describe whether the warning threshold is defined as absolute value or relative to split in |
'ABSOLUTE' |
fail_if_less_than |
Optional[float] |
Fail if score is less than the value specified in this argument. |
None |
fail_if_greater_than |
Optional[float] |
Fail if score is greater than the value specified in this argument. |
None |
fail_if_within |
Optional[Tuple[float, float]] |
Fail if |
None |
fail_if_outside |
Optional[Tuple[float, float]] |
Fail if |
None |
fail_threshold_type |
str |
Must be one of ["ABSOLUTE", "RELATIVE"]. Describe whether the fail threshold is defined as absolute value or relative to split in |
'ABSOLUTE' |
reference_split_name |
Optional[str] |
Name of the reference split used for the "RELATIVE" threshold type. If not specified and |
None |
reference_model_name |
Optional[str] |
Name of the reference model used for the "RELATIVE" threshold type. |
None |
description |
Optional[str] |
Text description of the test. |
None |
overwrite |
bool |
If set to |
False |
Examples of adding performance test with absolute threshold:
# Performance test on multiple data splits with a single value threshold
>>> tru.tester.add_performance_test(
test_name="Accuracy Test 1",
data_split_names=["split1_name", "split2_name"],
metric="CLASSIFICATION_ACCURACY",
warn_if_less_than=0.85,
fail_if_less_than=0.82
)
# Alternative, we can also specify data split name using regex
>>> tru.tester.add_performance_test(
test_name="Accuracy Test 2",
data_split_name_regex=".*-California", # this test will be run on all data splits where the name contains "-California"
all_data_collections=True, # this test will be applicable to all data collections
metric="CLASSIFICATION_ACCURACY",
warn_if_less_than=0.85,
fail_if_less_than=0.82
)
# Performance test using a segment with a single value threshold
>>> tru.tester.add_performance_test(
test_name="Accuracy Test 3",
data_split_names=["split1_name", "split2_name"],
segment_group_name="segment_group_name",
segment_name="segment_name",
metric="FALSE_POSITIVE_RATE",
warn_if_greater_than=0.05,
fail_if_greater_than=0.1
)
# Performance test with a range threshold
>>> tru.tester.add_performance_test(
test_name="Accuracy Test 4",
data_split_names=["split1_name", "split2_name"],
metric="FALSE_NEGATIVE_RATE",
warn_if_outside=(0.05, 0.1),
fail_if_outside=(0.02, 0.15)
)
Examples of adding performance test with relative threshold:
# Explicitly specifying the reference split of a RELATIVE threshold
>>> tru.tester.add_performance_test(
test_name="Accuracy Test 5",
data_split_names=["split1_name", "split2_name"],
metric="CLASSIFICATION_ACCURACY",
warn_if_less_than=-0.05, # warn if accuracy of split < (1 + -0.05) * accuracy of reference split
warn_threshold_type="RELATIVE",
fail_if_less_than=-0.08,
fail_threshold_type="RELATIVE",
reference_split_name="reference_split_name"
)
# Not explicitly specifying the reference split on a RELATIVE threshold means
# the reference split is each model's train split
>>> tru.tester.add_performance_test(
test_name="Accuracy Test 6",
data_split_names=["split1_name", "split2_name"],
metric="FALSE_POSITIVE_RATE",
warn_if_greater_than=0.02,
warn_threshold_type="RELATIVE",
fail_if_greater_than=0.021,
fail_threshold_type="RELATIVE"
)
# RELATIVE test using reference model instead of reference split
>>> tru.tester.add_performance_test(
test_name="Accuracy Test 7",
data_split_names=["split1_name", "split2_name"],
metric="CLASSIFICATION_ACCURACY",
warn_if_less_than=0,
warn_threshold_type="RELATIVE",
fail_if_less_than=-0.01,
fail_threshold_type="RELATIVE",
reference_model_name="reference_model_name"
# RELATIVE test using both reference model and reference split
>>> tru.tester.add_performance_test(
test_name="Accuracy Test 8",
data_split_names=["split1_name", "split2_name"],
metric="CLASSIFICATION_ACCURACY",
warn_if_less_than=0,
warn_threshold_type="RELATIVE",
fail_if_less_than=-0.01,
fail_threshold_type="RELATIVE",
reference_model_name="reference_model_name",
reference_split_name="reference_split_name"
)
add_stability_test(self, test_name, metric='DIFFERENCE_OF_MEAN', *, comparison_data_split_names=None, comparison_data_split_name_regex=None, base_data_split_name=None, all_data_collections=False, data_collection_names=None, segments=None, warn_if_less_than=None, warn_if_greater_than=None, warn_if_within=None, warn_if_outside=None, fail_if_less_than=None, fail_if_greater_than=None, fail_if_within=None, fail_if_outside=None, description=None, overwrite=False)
¶
Add a stability test to the current data collection in context. To set warning condition, please provide one of [warn_if_less_than, warn_if_greater_than, warn_if_within, warn_if_outside].
Similarly, to set fail condition please provide one of [fail_if_less_than, fail_if_greater_than, fail_if_within, fail_if_outside].
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
test_name |
str |
The name of the test. |
required |
metric |
str |
Stability metric for the test. Must be one ["WASSERSTEIN", "DIFFERENCE_OF_MEAN", "POPULATION_STABILITY_INDEX"] |
'DIFFERENCE_OF_MEAN' |
comparison_data_split_names |
Optional[Sequence[str]] |
List of the data splits that we want to use for the test. |
None |
comparison_data_split_name_regex |
Optional[str] |
Regex of the data split name that we want to use for the test (future data splits that match this naming pattern will automatically be included in the test). |
None |
base_data_split_name |
Optional[str] |
Name of the reference data split to use as the comparison baseline for the test. If |
None |
data_collection_names |
Optional[Sequence[str]] |
List of the data collections for the test. If not specified, the test will only apply to the current data collection in context. |
None |
all_data_collections |
bool |
If set to |
False |
segments |
Optional[Sequence[Tuple[str, str]]] |
List of |
None |
warn_if_less_than |
Optional[float] |
Warn if score is less than the value specified in this argument. |
None |
warn_if_greater_than |
Optional[float] |
Warn if score is greater than the value specified in this argument. |
None |
warn_if_within |
Optional[Tuple[float, float]] |
Warn if |
None |
warn_if_outside |
Optional[Tuple[float, float]] |
Warn if |
None |
fail_if_less_than |
Optional[float] |
Fail if score is less than the value specified in this argument. |
None |
fail_if_greater_than |
Optional[float] |
Fail if score is greater than the value specified in this argument. |
None |
fail_if_within |
Optional[Tuple[float, float]] |
Fail if |
None |
fail_if_outside |
Optional[Tuple[float, float]] |
Fail if |
None |
description |
Optional[str] |
Text description of the test. |
None |
overwrite |
bool |
If set to |
False |
Examples:
>>> tru.tester.add_stability_test(
test_name="Stability Test",
comparison_data_split_names=["split1_name", "split2_name"],
base_data_split_name="reference_split_name",
metric="DIFFERENCE_OF_MEAN",
warn_if_outside=[-1, 1],
fail_if_outside=[-2, 2]
)
delete_tests(self, test_name=None, test_type=None, data_split_name=None, segment_group_name=None, segment_name=None, metric=None)
¶
Delete tests.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
test_name |
Optional[str] |
Only delete tests with the given name. |
None |
test_type |
Optional[str] |
Only delete tests of this type. Must be one of ["performance", "stability", "fairness"] or None. If None, delete all test types. Defaults to None. |
None |
data_split_name |
Optional[str] |
Only delete tests associated with this data split. Defaults to None. |
None |
segment_group_name |
Optional[str] |
Only delete tests associated with this segment group. Defaults to None. |
None |
segment_name |
Optional[str] |
Only delete tests associated with this segment. Defaults to None. |
None |
metric |
Optional[str] |
Only delete tests associated with this metric. Defaults to None. |
None |
get_model_leaderboard(self, sort_by='performance', wait=True)
¶
Get the summary of test outcomes for all models in the data collection.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
sort_by |
str |
Rank models according to the test type specified in this arg (models with the fewest test failures will be at the top). Must be one of ["performance", "stability", "fairness"]. Defaults to "performance". |
'performance' |
wait |
bool |
Whether to wait for test results to finish computing. Defaults to True. |
True |
Returns:
| Type | Description |
|---|---|
ModelTestLeaderboard |
A |
get_model_test_results(self, data_split_name=None, comparison_models=None, test_types=None, wait=True)
¶
Get the test results for the model in context.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
data_split_name |
Optional[str] |
If provided, filters to the tests associated with this split. |
None |
comparison_models |
Optional[Sequence[str]] |
If provided, compare the test results against this list of models. |
None |
test_types |
Optional[Sequence[str]] |
If provided, filter to only the given test-types. Must be a subset of ["performance", "stability", "fairness"] or None (which defaults to all). Defaults to None. |
None |
wait |
bool |
Whether to wait for test results to finish computing. |
True |
Returns:
| Type | Description |
|---|---|
ModelTestResults |
A |
get_model_tests(self, data_split_name=None)
¶
Get the details of all the model tests in the current data collection or the model tests associated with the given data split.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
data_split_name |
Optional[str] |
If provided, filters to the tests associated with this split. |
None |
Returns:
| Type | Description |
|---|---|
ModelTestDetails |
A |