Evaluate and Monitor LLM Apps using TruEra¶
In this example, we will build a first prototype RAG to answer questions from the Insurance Handbook PDF. Using TruLens, we will define different feedback evaluations, ingest data into TruEra and then iterate to ensure the app is honest, harmless and helpful.
To get started quickly with TruEra Diagnostics, make sure the Python SDK is installed (see Installation and Access), then follow the guidance below.
Connecting to TruEra¶
Connecting to the TruEra platform is a straightforward authentication process using a token. To make the connection, you'll need to provide the TRUER_URL and your TOKEN.
Replace the <TRUERA_URL> placeholder with the URL string "http://app.truera.net" (or any url provided to you) below in step 4.
To generate your authentication token:
- Open your avatar in the Web App toolbar.
-
Click Authentication, then click GENERATE CREDENTIALS.
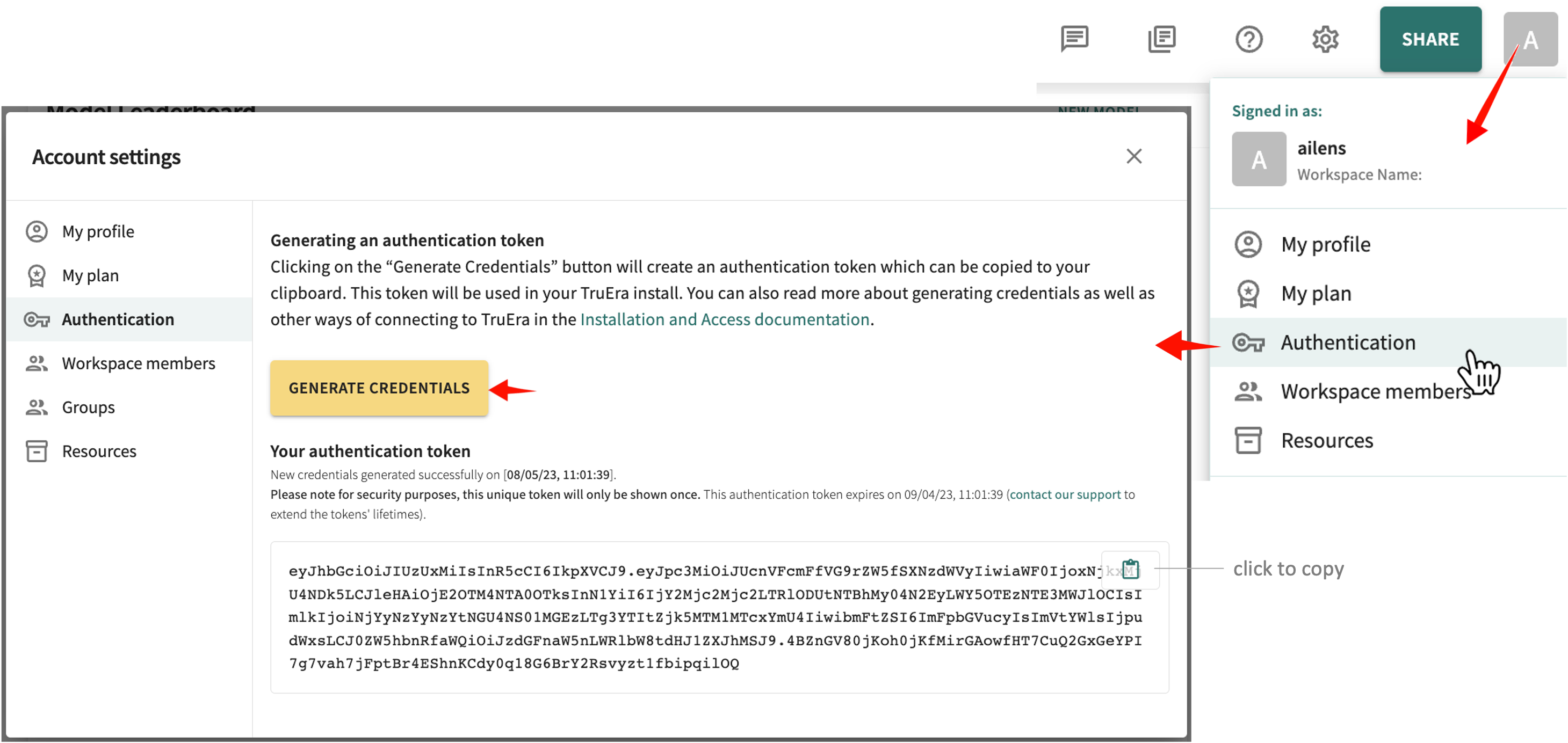
click and hold to enlarge -
Click the clipboard icon to copy the token.
-
Replace the
<TRUERA_TOKEN>placeholder shown next by pasting in the copied token.TRUERA_URL = "<TRUERA_URL>" TOKEN = "<TRUERA_TOKEN>" from truera.client.truera_authentication import TokenAuthentication from truera.client.experimental.truera_generative_text_workspace import TrueraGenerativeTextWorkspace tru = TrueraGenerativeTextWorkspace( CONNECTION_STRING, TokenAuthentication(TOKEN) ) auth = TokenAuthentication(TOKEN) tru = TrueraWorkspace(TRUERA_URL, auth)
Evaluate a simple RAG application using TruEra¶
Once having established a TruEra workspace object, let's proceed to define an LLM Application.
Step 1: Setup API Keys¶
Let's start by configuring the required API keys for our application. We will be using OpenAI in this notebook
import sys
import os
import openai
# Set your API keys. If you already have them in your var env., you can skip these steps.
OPENAI_API_KEY=""
OPENAI_API_ORG="" #Optional
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
os.environ["HUGGINGFACE_API_KEY"] = OPENAI_API_ORG
Step 2: Setup a Vector store¶
Get data to create our knowledge base for our RAG. Initialize a simple paragraph about the University of Washington to be used as our source.
university_info = """
The University of Washington, founded in 1861 in Seattle, is a public research university
with over 45,000 students across three campuses in Seattle, Tacoma, and Bothell.
As the flagship institution of the six public universities in Washington state,
UW encompasses over 500 buildings and 20 million square feet of space,
including one of the largest library systems in the world.
"""
Create a Vector Store and add the university_info to the embedding database.
import chromadb
from chromadb.utils.embedding_functions import OpenAIEmbeddingFunction
chroma_client = chromadb.Client()
vector_store = chroma_client.get_or_create_collection(
name="Universities",
embedding_function=OpenAIEmbeddingFunction(
api_key=OPENAI_API_KEY,
organization_id=OPENAI_API_ORG,
model_name="text-embedding-ada-002"
)
)
vector_store.add("uni_info", documents=university_info)
Step 3: Build a RAG application¶
We will be building a RAG application from scratch (without using an abstraction framework). You can use the instrument module from trulens-eval package as a declarator to easily define a RAG application that can start logging to TruEra
from trulens_eval.tru_custom_app import instrument
from openai import OpenAI
oai_client = OpenAI(
api_key=OPENAI_API_KEY,
organization=OPENAI_API_ORG
)
class RAG_from_scratch:
@instrument
def retrieve(self, query: str) -> list:
"""
Retrieve relevant text from vector store.
"""
results = vector_store.query(
query_texts=query,
n_results=1
)
return results['documents'][0]
@instrument
def generate_completion(self, query: str, context_str: list) -> str:
"""
Generate answer from context.
"""
completion = oai_client.chat.completions.create(
model="gpt-3.5-turbo",
temperature=0,
messages=
[
{"role": "user",
"content":
f"We have provided context information below. \n"
f"---------------------\n"
f"{context_str}"
f"\n---------------------\n"
f"Given this information, please answer the question: {query}"
}
]
).choices[0].message.content
return completion
@instrument
def query(self, query: str) -> str:
context_str = self.retrieve(query)
completion = self.generate_completion(query, context_str)
return completion
rag_app = RAG_from_scratch()
# you can test your by running rag_app.query("Where is the University of Washington?")
Step 4: Set up feedback functions¶
We can easily define feedback functions to evaluate our LLM app responses across various dimensions. Here we'll use groundedness, answer relevance and context relevance to detect hallucination.
from trulens_eval import Feedback, Select
from trulens_eval.feedback import Groundedness
from trulens_eval.feedback.provider.openai import OpenAI as fOpenAI
import numpy as np
# Initialize provider class
fopenai = fOpenAI()
grounded = Groundedness(groundedness_provider=fopenai)
# Define a groundedness feedback function
f_groundedness = (
Feedback(grounded.groundedness_measure_with_cot_reasons, name = "Groundedness")
.on(Select.RecordCalls.retrieve.rets.collect())
.on_output()
.aggregate(grounded.grounded_statements_aggregator)
)
# Question/answer relevance between overall question and answer.
f_qa_relevance = (
Feedback(fopenai.relevance_with_cot_reasons, name = "Answer Relevance")
.on(Select.RecordCalls.retrieve.args.query)
.on_output()
)
# Question/statement relevance between question and each context chunk.
f_context_relevance = (
Feedback(fopenai.qs_relevance_with_cot_reasons, name = "Context Relevance")
.on(Select.RecordCalls.retrieve.args.query)
.on(Select.RecordCalls.retrieve.rets.collect())
.aggregate(np.mean)
)
Step 5: Add Project¶
Create a Truera project using the tru workspace object that we defined above
PROJECT_NAME = "RAG_Project_Avinash"
APP_NAME = "RAG app v2"
tru.add_project(PROJECT_NAME)
Step 6: Add Experimental Data¶
First let's ingest in experimental mode by setting the appropriate config and wrapping the rag app
from truera.client.experimental.truera_generative_text_workspace import LLMDatasetConfig, Experiment
dataset_config = LLMDatasetConfig(config=Experiment())
tru_recorder = tru.wrap_custom_app(
app=rag_app,
project_name=PROJECT_NAME,
app_name=APP_NAME,
feedbacks = [f_groundedness, f_qa_relevance, f_context_relevance],
dataset_config=dataset_config
)
Call the wrapper on a few sample queries
queries = [
"When was the University of Washington founded?",
"How many campuses does the University of Washington have?"
]
with tru_recorder as c:
for q in queries:
print(f"Query: {q}")
response = tru_recorder.app.query(q)
print(f"Response: {response}\n")
Step 7: Analyze in the UI¶
Head over to your UI by clicking on "http://app.truera.net" (or any url provided to you). Open the project that you have just created and click on Experiments page to see your app along with the traces ingested. Click here to learn more.
Ingest Data in Production Mode¶
To ingest data in production mode, change the dataset configuration in step 11 and follow the same process
from truera.client.experimental.truera_generative_text_workspace import LLMDatasetConfig, Production
dataset_config_prod=LLMDatasetConfig(config=Production())
tru_recorder = tru.wrap_custom_app(
app=rag_app,
project_name=PROJECT_NAME,
app_name=APP_NAME,
feedbacks = [f_groundedness, f_qa_relevance, f_context_relevance],
dataset_config=dataset_config
)
with tru_recorder as c:
for q in queries:
print(f"Query: {q}")
response = tru_recorder.app.query(q)
print(f"Response: {response}\n")
Once you have ingest production data, you can setup your monitoring dashboards. Click here to learn more.
Click Next below to continue.